
Next week, as part of a general reworking of its editorial page, the LA Times is staring “wikatorials” – “an online feature that will empower you to rewrite Los Angeles Times editorials.”
(via Dan Gillmor)
UPDATE: “Upheaval on Los Angeles Time Editorial Pages” in NY Times.
Author Archives: ben vershbow
web news as gated community
Just found out about this on diglet.. Launched in April, The National Digital Newspaper Program (NDNP) is a joint effort of the Library of Congress and the National Endowment of the Humanities to create a comprehensive web archive of the nation’s public domain newspapers.
Ultimately, over a period of approximately 20 years, NDNP will create a national, digital resource of historically significant newspapers from all the states and U.S. territories published between 1836 and 1922. This searchable database will be permanently maintained at the Library of Congress (LC) and be freely accessible via the Internet.
(A similar project is getting underway in France.)
It’s frustrating that this online collection will stop at 1922. Ordinary libraries maintain up-to-date periodical archives and make them available to anyone if they’re willing to make the trip. But if they put those collections on the web, they’ll be sued. Archives are one of the few ways newspapers have figured out to make money on the web, so they’re not about to let libraries put their microfilm and periodical reading rooms online. The paradigm has flipped.. in print, you pay for the current day’s edition, but the following day it ends up in the trash, or wrapping a fish. The passage of 24 hours makes it worthless. On the web, most news is free. It’s the fish wrap that costs you.
The web has utterly changed what things are worth. For most people, when a news site asks them to pay, they high tail it out of there and never look back. Even being asked to register is enough to deter many readers. But come September, the New York Times will start charging a $50 annual fee for what it considers its most unique commodities – editorials, op-eds, and selected other features. Is a full subscription site not far off? With their prestige and vast readership, the Times might be able to pull it off. But smaller papers are afraid to start charging, even as they watch their print circulation numbers plummet. If one paper puts up a tollbooth, they instantly become irrelevant to millions of readers. There will always be a public highway somewhere nearby.
A friend at the Columbia School of Journalism told me that the only way newspapers can be profitable on the web is if they all join together in some sort of league and charge bulk subscription fees for universal access. If there’s a wholesale move to the pay model, then readers will have no choice but to shell out. It will be like paying for cable service, where each newspaper is a separate channel. The only time you register is when you pay the initial fee. From then on, it’s clear sailing.
It’s a compelling idea, but could just be collective suicide for the newspapers. There will always be free news on offer somewhere. Indian and Chinese wire services might claim the market while the prestigious western press withers away. Or people will turn to state-funded media like the BBC or Xinhua. Then again, people might be willing to pay if it means unfettered access to high quality, independent journalism. And with newspapers finally making money on web subscriptions, maybe they’d start loosening up about their archives.
uncyclopedia: the inevitable wikipedia parody

![]() Uncyclopedia is “the content-free encyclopedia that anyone can edit.” Its definition of “book” is actually kind of interesting: “Bound Offline Organized Knowledge.”
Uncyclopedia is “the content-free encyclopedia that anyone can edit.” Its definition of “book” is actually kind of interesting: “Bound Offline Organized Knowledge.”
“an invaluable resource that they had an extremely limited role in creating”
Good piece today in Wired on the transformation of scientific journals. There’s a general feeling that commercial publishers like Reed Elsevier enjoy unreasonable control over an evolving body of research that should be freely available to the public. With exorbitant subscription fees, affordable only for large institutions, most journals are effectively inaccessible, and the authors retain few or no reproduction rights. Recently, however, free article databases have sprung up on the web – The Public Library of Science (PLoS), BioMed Central, and NIH’s PubMed – some of which, like PLoS, have begun publishing their own journals. It’s a welcome change, considering how much labor and treasure is poured into scientific publications (from funders, private and public, and from the scientists themselves), and yet how little is gotten in return. Shifting to a non-profit model, as PLoS has done, preserves much of the financial architecture that supports the production of journals, but totally revolutionizes the distribution.
PLoS journals are free and allow authors to retain their copyrights, as long as they allow their work to be freely shared and distributed (with full credit given, naturally). They also require that authors pay $1,500 from their grants, or directly from their sponsors or institutions, to have their work published. These groups pay the bulk of the $10 billion that goes to scientific and medical publishers each year, and what do they get in return? Limited access to the research they funded, and no right to reuse the information.
“It’s ridiculous to give publishers complete control of an invaluable resource that they had an extremely limited role in creating,” Eisen said (Eisen teaches genetics and is a founder of PLoS).
But what is in many ways the tougher question is how to shift the architecture of prestige – peer review – to these new kinds of journals.
building frontier networks
The $100 laptop project – the MIT-led initiative to distribute cheap, network-enabled computers to schools throughout the developing world – is moving ahead, but it’s far from clear whether it will succeed. Today Wired discusses some of the daunting physical challenges of deploying technology in places where there isn’t even electricity, let alone a wireless broadband network. As far as energy is concerned, the MIT team is trying to make the computers as self-sustaining as possible, experimenting with hand cranks (like a wind-up watch) and “parasitic power,” where the user’s typing constantly charges the battery. Then there is the problem of networks. The vision driving the project is one of delivering the resources of the web to communities that are cut off from libraries and the general flow of information. But extending the gossamer strands of the web requires robust architecture. Dumping cheap laptops in village schools won’t achieve much if you can’t connect the dots.

![]()

Wired mentions geekcorps, a group that coordinates skilled technology volunteers around the world “to teach communities how use innovative and affordable information and communication technologies to solve development problems.” One of their trademark innovations is the “BottleNet” – a method for setting up improvised Wi-Fi relay networks with “do-it-yourself antennas,” first employed in geekcorp’s Mali project:
The do-it-yourself (DIY) antenna designs were based on information gathered from numerous sources, including standard ham radio operator reference manuals, books on building wireless community networks, numerous DIY wireless sites on the Internet, and from the past experiences of GCM volunteers with wireless antennas. Changes to the designs were made to incorporate materials that are easily available in Mali (plastic water bottles, used valve stems from motorbikes, window screen mesh, television and low cost coaxial cables, etc.) to minimize the technical skills needed to build an antenna and to reduce costs.
Something about these ad hoc creations, patched together with junk – the scraps of western industry – speaks eloquently of the fragility of our grand networked enterprise.
images: (left) kids with Panasonic Toughbooks at the Nicholas and Elaine Negroponte School in Cambodia (from Wired); (right) BottleNet antenna in Mali
Bayesian news by email
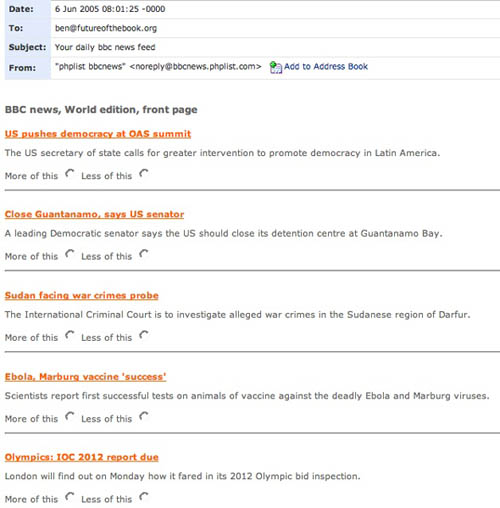
Another interesting prototype from BBC Backstage: news feeds delivered by email with Bayesian filtering. In other words, you can flag the kind of messages you want to receive more of, and the kind you want to receive less of, purifying the signal, as it were. This kind of filtering was first developed to deal with spam. Here’s what it looks like in your mail viewer:
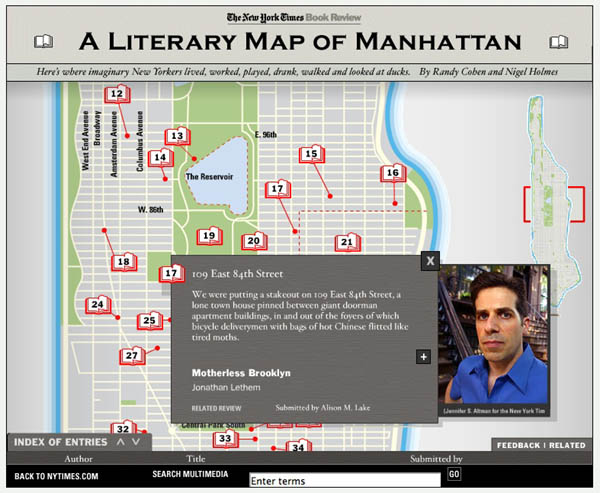
a literary map of manhattan
Maps maps maps. Everyone’s playing with maps as interface (see here and here). Check out this multimedia feature at the NY Times. Doesn’t go very deep, but fun all the same. Each item was reader-submitted over the past month – a collective effort to map the rich fictional life of Manhattan. They should do one of these for Brooklyn.
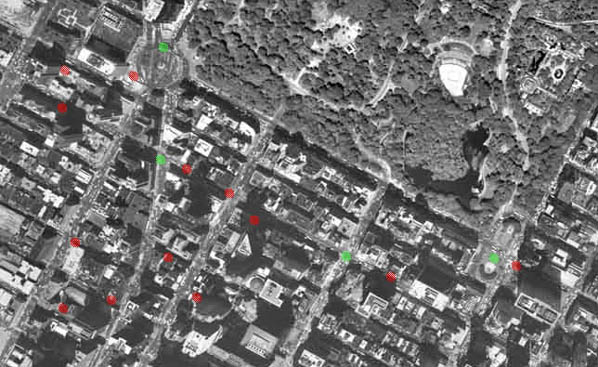
Reminds me of Mr. Beller’s Neighborhood. Each of the red dots below links to a story or article set in that location.
remixing the news
There’s been an explosion of creative tinkering since the BBC opened up its API (applications programming interface) last month. An API is a window into a site’s code and content allowing techie types to build new applications with BBC material. It’s really worth going over to the BBC Backstage blog to take a look at the first batch of prototypes and demos. The majority are clever splicings of BBC data – news, traffic reports, images etc. – with Google Maps (everyone’s favorite lately), not unlike chicagocrime.org. Other notable examples: an RSS feed of BBC complaints; a feature that allows you to tag articles and read tags left by other readers; and a nice “tag soup” visualization of financial news.
Correction: A reader kindly pointed out that BBC Backstage hasn’t actually released APIs yet (though they intend to soon). The projects I’ve referenced use BBC feeds, or have scraped content directly from the BBC site. APIs are to follow soon (more info here). When they do, the scaping process will become much cleaner. For now, the BBC welcomes projects that “use our stuff to build your stuff” the rough-and-tumble way, and is happy to showcase them on the Backstage site.
The API is becoming a powerful tool for creative reinvention of the web. Back in April, I wrote about Dan Gillmor’s piece on “Web 3.0”.. Web 1.0 was the early web, a place you went to read – a series of interconnected brochures. Web 2.0 is the “read-write” web – it’s a place you go to interact. Web 3.0 is where we start weaving the disparate pieces into new forms. APIs let you do this. You take one application and design a new front end that shows your point of view. Or you take two applications and mix them together, creating something new and illuminating. Right now, Web 2.0 is pretty well in place. The tools for self-expression and interaction are pretty accessible – email, chat, blogs, etc. But the weaving tools required for 3.0 are available only to advanced users. We’ll see if that changes.
Here are grabs from four of the map prototypes at BBC Backstage:
Traffic Maps:
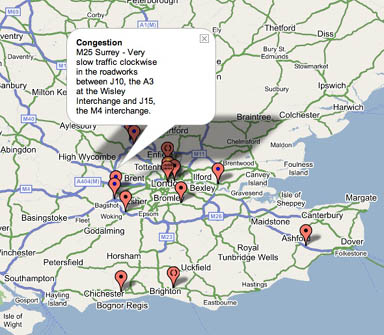
Map of BBC London Jam Cams:
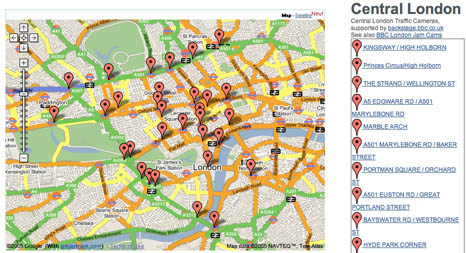
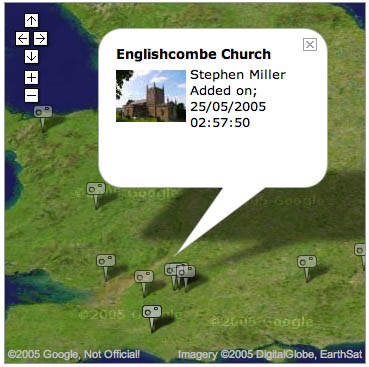
Photo Mapping:
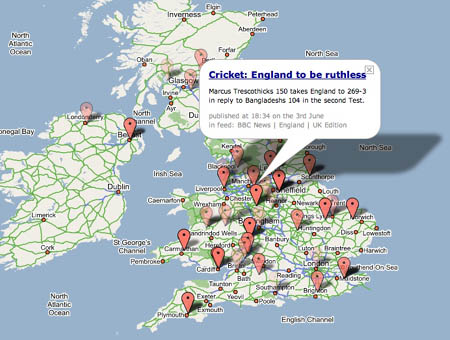
Map of the News:
For more analysis, check out this article on O’Reilly Radar.
80 years of the New Yorker on disc
The New Yorker has never seemed terribly interested in going digital. Despite maintaining the obligatory website, with a smattering of free content and online features, the magazine exists somewhat apart from the daily swarm of the web. The print format still works quite well for them, and they have the legions of loyal subscribers to prove it.
But their latest publishing project does take them into digital territory. This October, in a big legacy move, the venerable weekly will release 4,109 issues – every single page since the February 1925 founding and the 80th anniversary issue this year – on an eight-DVD set. “The Complete New Yorker” (see NY Times story) will go for about $100 (though Walmart is already listing it for $59.22), and will also contain a 123-page book with an introduction by editor David Remnick. A big improvement on microfilm, the discs will allegedly be searchable by computer, though how granular the search is remains to be seen. For it to be more than just a collector’s item, it should be fully structured and offer fine-toothed find functionality. Remnick confirms, however, that readers will have the option of browsing just the cartoons (as many of us do).
visual bookmarks
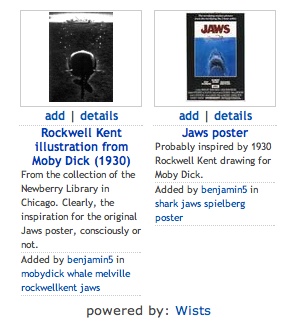 Wists is a visual bookmarking system for the web, doing for images what del.icio.us does for web pages. It’s like browsing the web with a camera, or creating your own hand-selected Google image search. Find an image you want to keep track of and Wists will create a thumbnail for you, linking back to the original site. If it’s a whole page you want to capture, Wists will take an automatic screenshot of the entire page. Add a title, tags and description and it goes into the system – a photo album of the web. Much like del.icio.us, Wists arranges popular tags on the sidebar and allows you to browse the latest entries. It also enables you to add other users’ bookmarks to your own gallery, clearing the slate for your own tags and descriptions. Best of all, it keeps track of people you’ve taken items from, and people who have taken items from you. Trails become apparent and the archive becomes interconnected. Here’s a grab of my “jaws” tag page – combing around for images, I found an amusing juxtaposition.
Wists is a visual bookmarking system for the web, doing for images what del.icio.us does for web pages. It’s like browsing the web with a camera, or creating your own hand-selected Google image search. Find an image you want to keep track of and Wists will create a thumbnail for you, linking back to the original site. If it’s a whole page you want to capture, Wists will take an automatic screenshot of the entire page. Add a title, tags and description and it goes into the system – a photo album of the web. Much like del.icio.us, Wists arranges popular tags on the sidebar and allows you to browse the latest entries. It also enables you to add other users’ bookmarks to your own gallery, clearing the slate for your own tags and descriptions. Best of all, it keeps track of people you’ve taken items from, and people who have taken items from you. Trails become apparent and the archive becomes interconnected. Here’s a grab of my “jaws” tag page – combing around for images, I found an amusing juxtaposition.
These are the kind of basic curatorial tools that would be great on Flickr. Currently, you are only able to apply tags to your own photos, or the those of friends, family or mutual contacts. But part of the fun of Flickr is browsing the photos of total strangers. You can comment on any photo or mark it as a favorite, but there is no way to curate your own collection of images from the community at large. Wists suggests how the gap between del.icio.us and Flickr might be bridged.