
Over at Teleread, David Rothman has a pair of posts about Google’s new desktop RSS reader and a couple of new technologies for creating “offline web applications” (Google Gears and Adobe Apollo), tying them all together into an interesting speculation about the possibility of offline networked books. This would mean media-rich, hypertextual books that could cache some or all of their remote elements and be experienced whole (or close to whole) without a network connection, leveraging the local power of the desktop. Sophie already does this to a limited degree, caching remote movies for a brief period after unplugging.
Electronic reading is usually prey to a million distractions and digressions, but David’s idea suggests an interesting alternative: you take a chunk of the network offline with you for a more sustained, “bounded” engagement. We already do this with desktop email clients and RSS readers, which allow us to browse networked content offline. This could be expanded into a whole new way of reading (and writing) networked books. Having your own copy of a networked document. Seems this should be a basic requirement for any dedicated e-reader worth its salt, to be able to run rich web applications with an “offline” option.
Category Archives: RSS
NYTimes reader
[editor’s note: The New York Times released a new software reader. It is Windows only. No Mac compatibility at this time. We asked Christine Boese, of serendipit-e.com, to post her thoughts on the matter.]

I got this off another news clip service I’m on…
NYT Finally Creates a Readable Online Newspaper (Slate)
Jack Shafer: About six months ago, I canceled my New York Times subscription because I had found the newspaper’s redesigned Web site to be superior to the print Times. I’ve now abandoned the Web version for the New York Times Reader, a new computer edition that has entered general beta release.
I went around to try to sign up for it and get a look. I couldn’t, because the Times IT dept overlooked making its beta available for Macs. I scanned through the screenshots, tho, and the comments on the blog preview of features, sneek peek #1 and #2.
Jack Shafer isn’t exactly an expert in interactive design, so I don’t know if his endorsement means anything other than, "Gee whiz, here’s a neato new thing!".
My initial impressions are that it looks like the International Herald Tribune
with a horizontal orientation I just can’t stand (the Herald Tribune often requires horizontal scrolling, and it’s far easier to read the printable version of stories). Yes, I see there is a narrow screen screenshot, but I’m thinking more about the text flow nightmares this design must cause.
But I think I have bigger reservations about the entire concept behind the Times Reader beta.
Here’s just a summary of questions I’d want answered, if I were actually able to test the beta:
- How is re-creating a facsimile of a print newspaper online a step forward for interactive media? Is it really, or is it just a kind of "horseless carriage" retrenchment? Shafer talks about some non-print-like pages that tell you what you’ve read or haven’t read, to assist browsing and search, but notes that the archives are thin. I wonder if the Times "Most Popular" feature makes the cut.
- Code. The big deal here is that it uses Microsoft .NET and advancers on Vista technology. I smell a walled garden. Is this XML-compatible? RSS-enabled? Is it even in HTML code that can be easily copied and pasted? (Shafer’s piece says it can be, but I want to see for myself) W3 validated? Does its content management system have permalinks? How do bookmarks work?
- Hyperlinks. Will the text accomodate them? Will the Times use them? Or by anchoring themselves firmly in a "reader" technology, perhaps a completely web-independent application, is the Times trying to go beyond simply a code-walled garden and also create a strong CONTENT walled garden as well? Is this a variant of TimesSelect on speed?
- Audience. Presumably the Times has some research that shows a need to court its paper-bound print-loving audience to its online products by making the online products more like the print products.
- Usability and Design. I’ve already mentioned the Mac incompatiblity. What other usability and design issues are present in this Times Reader technology? I’ll leave that to people who actually get use it.
But my question about audience is this: is there a REASON to make heroic efforts to lure print readers online? Isn’t the bigger issue trying to keep print readers attached to print, so that the ad-driven print editions don’t have to go the way of the dinosaur? The online news audience is already massive, and (Pew, Poynter) studies show that during the recent wars, large numbers of people were turning away from traditional news providers and outlets to seek out other sources of information, particularly international information, on the Internet and with news feed readers (RSS/Atom).
So in a competitive online news landscape, the Times makes a strategic turn to become more like its print product? And this will lure large numbers of online news readers back exclusively to the Times exactly HOW? Especially if it is a walled garden that doesn’t integrate well into the Blogosphere or in RSS news feed readers?
People like Terry Heaton and other media consultants (Heaton has a terrific blog, if you haven’t found it yet) are going out and telling traditional news media outlets that they have to move more strongly into an environment of UNBOUND media, to make their products more maleable for an unbound Internet environment. It appears the Times is not a company that has purchased Heaton’s services lately.
From the screenshots I’ve seen, there seems to be very little functionality or interactive user-customizable features at all. I don’t know. Color me stupid, but my gut reaction is that this is nothing more than another variant of the exact PDF version of the paper that the Times put out, only perhaps with better text searching features and dynamic text flow (meaning I’d bet it is XML-based instead of PDF-based, only with some custom-built or Microsoft-blessed walled garden DTD).
You know, for the money the Times spent on this (and the experienced journalists the Times Group laid off this past year), I’d have thought the best use of resources for a big media company would be to develop a really KILLER RSS feed reader, one that finally gets over the usability threshold that keeps feed readers in "Blinking 12-land" for most casual Internet users.
I mean, I know there are a lot of good feed readers out there (I favor Bloglines myself), but have any of you tried to convert non-techie co-workers into using a feed reader lately? I can’t for the LIFE of me figure out why there’s so much resistance to something so purely wonderful and empowering, something I believe is clearly the killer app on par with the first Mosaic browser in 1993. But because feed readers caught on bottom up instead of top down, there’s not only usability problems for the broadest audiences, there’s also a void at the top of the technology industry, by companies that fail to catch on to the RSS vision, mainly because they didn’t think it up themselves.
ebook ipod rumored
 Engadget has it from inside sources at Apple that a next-generation iPod is in the works with a larger screen and a full-fledged text reader:
Engadget has it from inside sources at Apple that a next-generation iPod is in the works with a larger screen and a full-fledged text reader:
…two bits from separate, trustworthy insiders that Apple’s not satisfied merely vending Audible‘s books-on-digital-audio solution. With the iRex iLiad and Sony PRS-500 Portable Reader both right around the corner, is it possible the next iPod might catch the eBook bug? We’d say the possibility is very real, since according to a source at a major publishing house, they were just ordered to archive all their manuscripts — every single one — and send them over to Apple’s Cupertino HQ.
So Audible, huh? Interesting. They got a toehold in the market with audiobooks, and may now be making the transition to ebooks.
A separate trusted source let us know that the next iPod will have a substantial amount of screen real estate (as we’d all suspected), as well as a book reading mode that pumps up the contrast and drops into monochrome for easy reading. It’s no e-ink, sure, but a widescreen iPod would be well suited for the purpose, and according to our source, the books you’d buy (presumably through iTunes) won’t have an expiration…
I’d hope that such a device would have wifi, a web browser and an RSS reader that could be taken offline. I think that books will only be a part of the equation.
Teleread has the ebook standards angle.
wikipedia provides rss for articles
As noted in The Long Tail, RSS feeds have been added to Wikipedia articles. The feeds can be accessed by going to an article’s history page – links for RSS & Atom feeds are on the left side, under the “toolbox” heading.
They’ve done a good job with these: instead of sending you a new copy of the article every time changes are made, as is the case with most blogging software, the feed explains exactly what’s changed. Here’s a sample of what they look like. It’s not the most intuitive presentation if you’ve never edited Wikipedia, but it is useful once you learn to decode it:
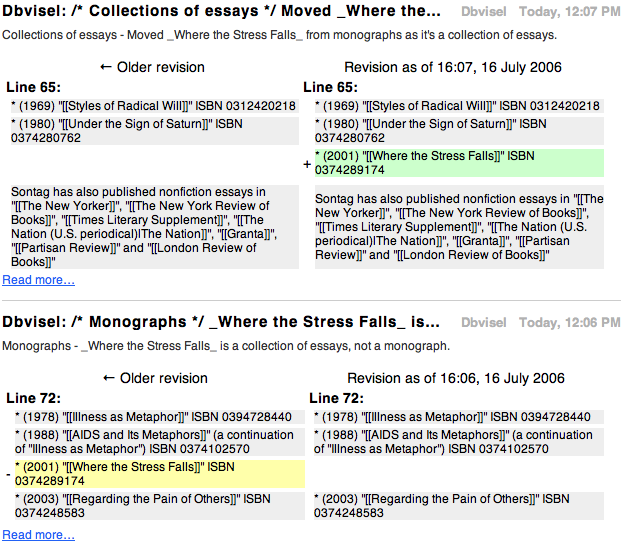
This is from the Wikipedia article on Susan Sontag; the feed is here, though the speed at which the Wikipedia changes suggests that you may no longer see these edits. This is actually two entries (the newest first) documenting a change that I made: I noticed that one of her books had been categorized incorrectly so I moved it to the correct category. In the bottom entry, I deleted Where the Stress Falls from the Monographs section: on the left side is the Monographs section before my deletion, on the right side in Monographs after my deletion. In the top entry, I added Where the Stress Falls to the Essays section. On the left is the section before my addition; on the right is the section after. The brackets, asterisks, and single quotes are the markup style used by Wikipedia. The yellow background is added to a new paragraph; green denotes a deleted paragraph. If you change existing text, changes are in red, much like MS Word’s track changes feature.
How useful is this? It might be too early to say: RSS is a useful building block, and once it exists, interesting uses tend to present themselves. I suspect it will prove most useful to casual Wikipedians, who update a small number of articles on a regular basis but don’t spend most of their time in the Wikipedia.
blogburst
A small Austin, TX-based company called Pluck is launching a new blog aggregation service called BlogBurst that will filter postings from hundreds of approved bloggers and syndicate their content to major news services (and eventually smaller niche publications as well). Tomorrow, BlogBurst lets rip its fire hose of content at a handful of major newspapers including USA Today publisher Gannett Co., The Washington Post, The San Francisco Chronicle, and local pubs The Austin American-Statesman and San Antonio Express. Some are calling this a further blurring of the boundary between mainstream and independent medias. Seems to me more like an expansion of the umbrella of the former and a buttressing of the oft-lamented “power law” with regard to the latter (how the most popular blogs get entrenched in an “A-list” in spite of popular belief a level playing field). The AP has more.
Any blogger can sign up with BlogBurst but some editorial body there decides which blogs go into the syndication feed. Presumably, if the thing takes off, they’ll start breaking it up into multiple feeds — some generalized, some specialized. Participating publishers are povided with “editorial management tools” called the “publisher workbench.” So if I’m a newspaper, I receive a daily dump of thousands of blog postings, broken down into different topic areas. I fiddle around with those in the workbench, choose the ones I want, and then plug them into various slots in my paper. Technically, it works like this (warning, acroynum blitz):
Content from the BlogBurst network is easily integrated into your site via simple JavaScript calls or robust SOAP or XML APIs.
Incidentally, the name blogburst is a bit of co-opted net jargon describing any coordinated effort by bloggers to flood the web with postings on a particular topic — usually some hot-button issue like the Jyllands-Posten Muhammad cartoons. Search “blogburst” today on Technorati and you’ll find a slew of right wing bloggers on a “guard the borders” rhetorical rampage (ha! idealistic me, I initially thought they meant the borders between mainstream and grassroots media!).
Meanwhile, as I write, thousands march down Broadway in New York — blogging, as it were, with their feet — in support of America’s illegal immigrants.
I wonder how the two-capital-Bs BlogBurst will deal with the political polarization of blogs.
reading fewer books
We’ve been working on our mission statement (another draft to be posted soon), and it’s given me a chance to reconsider what being part of the Institute for the Future of the Book means. Then, last week, I saw this: a Jupiter Research report claims that people are spending more time in front of the screen than with a book in their hand.
“the average online consumer spends 14 hours a week online, which is the same amount of time they watch TV.”
That is some 28 hours in front of a screen. Other analysts would say it’s higher, because this seems to only include non-work time. Of course, since we have limited time, all this screen time must be taking away from something else.
The idea that the Internet would displace other discretionary leisure activities isn’t new. Another report (pdf) from the Stanford Institute for the Quantitative Study of Society suggests that Internet usage replaces all sorts of things, including sleep time, social activities, and television watching. Most controversial was this report’s claim that internet use reduces sociability, solely on the basis that it reduces face-to-face time. Other reports suggest that sociability isn’t affected. (disclaimer – we’re affiliated with the Annenberg Center, the source of the latter report).
Regardless of time spent alone vs. the time spent face-to-face with people, the Stanford study is not taking into account the reason people are online. To quote David Weinberger:
“The real world presents all sorts of barriers that prevent us from connecting as fully as we’d like to. The Web releases us from that. If connection is our nature, and if we’re at our best when we’re fully engaged with others, then the Web is both an enabler and a reflection of our best nature.”
—Fast Company
Hold onto that thought and let’s bring this back around to the Jupiter report. People use to think that it was just TV that was under attack. Magazines and newspapers, maybe, suffered too; their formats are similar to the type of content that flourishes online in blog and written-for-the-web article format. But books, it was thought, were safe because they are fundamentally different, a special object worthy of veneration.
“In addition to matching the time spent watching TV, the Internet is displacing the use of other media such as radio, magazines and books. Books are suffering the most; 37% of all online users report that they spend less time reading books because of their online activities.”
The Internet is acting as a new distribution channel for traditional media. We’ve got podcasts, streaming radio, blogs, online versions of everything. Why, then, is it a surprise that we’re spending more time online, reading more online, and enjoying fewer books? Here’s the dilemma: we’re not reading books on screens either. They just haven’t made the jump to digital.
While there has been a general decrease in book reading over the years, such a decline may come as a shocking statistic. (Yes, all statistics should be taken with a grain of salt). But I think that in some ways this is the knock of opportunity rather than the death knell for book reading.
…intensive online users are the most likely demographic to use advanced Internet technology, such as streaming radio and RSS.
So it is ‘technology’ that is keeping people from reading books online, but rather the lack of it. There is something about the current digital reading environment that isn’t suitable for continuous, lengthy monographs. But as we consider books that are born digital and take advantage of the networked environment, we will start to see a book that is shaped by its presentation format and its connections. It will be a book that is tailored for the online environment, in a way that promotes the interlinking of the digital realm, and incorporates feedback and conversation.
At that point we’ll have to deal with the transition. I found an illustrative quote, referring to reading comic books:
“You have to be able to read and look at the same time, a trick not easily mastered, especially if you’re someone who is used to reading fast. Graphic novels, or the good ones anyway, are virtually unskimmable. And until you get the hang of their particular rhythm and way of storytelling, they may require more, not less, concentration than traditional books.”
—Charles McGrath, NY Times Magazine
We’ve entered a time when the Internet’s importance is shaping the rhythms of our work and entertainment. It’s time that books were created with an awareness of the ebb and flow of this new ecology—and that’s what we’re doing at the Institute.
useful rss
Hi. I’m Jesse, the latest member to join the staff here at the Institute. I’m interested in network effects, online communities, and emergent behavior. Right now I’m interested in the tools we have available to control and manipulate RSS feeds. My goal is to collect a wide variety of feeds and tease out the threads that are important to me. In my experience, mechanical aggregation gives you quantity and diversity, but not quality and focus. So I did a quick investigation of the tools that exist to manage and manipulate feeds.
Sites like MetaFilter and Technorati skim the most popular topics in the blogosphere.  But what sort of tools exist to help us narrow our focus? There are two tools that we can use right now: tag searches/filtering, and keyword searching. Tag searches (on Technorati) and tag filtering (on Metafilter) drill down to specific areas, like “books” or “books and publishing.” A casual search on MetaFilter was a complete failure, but Technorati, with its combination of tags and keyword search results produced good material.
But what sort of tools exist to help us narrow our focus? There are two tools that we can use right now: tag searches/filtering, and keyword searching. Tag searches (on Technorati) and tag filtering (on Metafilter) drill down to specific areas, like “books” or “books and publishing.” A casual search on MetaFilter was a complete failure, but Technorati, with its combination of tags and keyword search results produced good material.
There is also the Google Blog search. As Google puts it, you can ‘find blogs on your favorite topics.’ PageRank works, so PageRank applied to blogs should work too. Unfortunately it results in too many pages that, while higher ranked in the whole set of the Internet, either fail to be on topic or exist outside of the desired sub-spheres of a topic. For example, I searched for “gourmet food” and found one of the premier food blogs on the fourth page, just below Carpundit. Google blog search fails here because it can’t get small enough to understand the relationships in the blogosphere, and relies more heavily on text retrieval algorithms that sabotage the results.
Finally, let’s talk about aggregators. There is more human involvement in selecting sites you’re interested in reading. This creates a personalized network of sites that are related, if only by your personal interest. The problem is, you get what they want to write about. Managing a large collection of feeds can be tiresome when you’re looking for specific information. Bloglines has a search function that allows you to find keywords inside your subscriptions, then treat that as a feed. This neatly combines hand-picked sources with keyword or tag harvesting. The result: a slice of from your trusted collection of authors about a specific topic.
What can we envision for the future of RSS? Affinity mapping and personalized recommendation systems could augment the tag/keyword search functionality to automatically generate a slice from a small network of trusted blogs. Automatic harvesting of whole swaths of linked entries for offline reading in a bounded hypertext environment. Reposting and remixing feed content on the fly based on text-processing algorithms. And we’ll have to deal with the dissolving identity and trust relationships that are a natural consequence of these innovations.
explosion
![]() A Nov. 18 post on Adam Green’s Darwinian Web makes the claim that the web will “explode” (does he mean implode?) over the next year. According to Green, RSS feeds will render many websites obsolete:
A Nov. 18 post on Adam Green’s Darwinian Web makes the claim that the web will “explode” (does he mean implode?) over the next year. According to Green, RSS feeds will render many websites obsolete:
The explosion I am talking about is the shifting of a website’s content from internal to external. Instead of a website being a “place” where data “is” and other sites “point” to, a website will be a source of data that is in many external databases, including Google. Why “go” to a website when all of its content has already been absorbed and remixed into the collective datastream.
Does anyone agree with Green? Will feeds bring about the restructuring of “the way content is distributed, valued and consumed?” More on this here.
an ipod for text

When I ride the subway, I see a mix of paper and plastic. Invariably several passengers are lost in their ipods (there must be a higher ipod-per-square-meter concentration in New York than anywhere else). One or two are playing a video game of some kind. Many just sit quietly with their thoughts. A few are conversing. More than a few are reading. The subway is enormously literate. A book, a magazine, The Times, The Post, The Daily News, AM New York, Metro, or just the ads that blanket the car interior. I may spend a lot of time online at home or at work, but on the subway, out in the city, paper is going strong.
Before long, they’ll be watching television on the subway too, seeing as the latest ipod now plays video. But rewind to Monday, when David Carr wrote in the NY Times about another kind of ipod — one that would totally change the way people read newspapers. He suggests that to bounce back from these troubled times (sagging print circulation, no reliable business model for their websites), newspapers need a new gadget to appear on the market: a light-weight, highly portable device, easy on the eyes, easy on the batteries, that uploads articles from the web so you can read them anywhere. An ipod for text.
This raises an important question: is it all just a matter of the reading device? Once there are sufficient advances in display technology, and a hot new gadget to incorporate them, will we see a rapid, decisive shift away from paper toward portable electronic text, just as we have witnessed a widespread migration to digital music and digital photography? Carr points to a recent study that found that in every age bracket below 65, a majority of reading is already now done online. This is mostly desktop reading, stationary reading. But if the greater part of the population is already sold on web-based reading, perhaps it’s not too techno-deterministic to suppose that an ipod-like device would in fact bring sweeping change for portable reading, at least periodicals.
But the thing is, online reading is quite different from print reading. There’s a lot of hopping around, a lot of digression. Any new hardware that would seek to tempt people to convert from paper would have to be able to surf the web. With mobile web, and wireless networks spreading, people would expect nothing less (even the new Sony PSP portable gaming device has a web browser). But is there a good way to read online text when you’re offline? Should we be concerned with this? Until wi-fi is ubiquitous and we’re online all the time (a frightening thought), the answer is yes.
We’re talking about a device that you plug into your computer that automatically pulls articles from pre-selected sources, presumably via RSS feeds. This is more or less how podcasting works. But for this to have an appeal with text, it will have to go further. What if in addition to uploading new articles in your feed list, it also pulled every document that those articles linked to, so you could click through to referenced sites just as you would if you were online?
It would be a bounded hypertext system. You could do all the hopping around you like within the cosmos of that day’s feeds, and not beyond — you would have the feeling of the network without actually being hooked in. Text does not take up a lot of hard drive space, and with the way flash memory is advancing, building a device with this capacity would not be hard to achieve. Of course, uploading link upon link could lead down an infinite paper trail. So a limit could be imposed, say, a 15-step cap — a limit that few are likely to brush up against.
So where does the money come in? If you want an ipod for text, you’re going to need an itunes for text. The “portable, bounded hypertext RSS reader” (they’d have to come up with a catchier name –the tpod, or some such techno-cuteness) would be keyed in to a subscription service. It would not be publication-specific, because then you’d have to tediously sign up with dozens of sites, and no reasonable person would do this.
So newspapers, magazines, blogs, whoever, will sign licensing agreements with the tpod folks and get their corresponding slice of the profits based on the success of their feeds. There’s a site called KeepMedia that is experimenting with such a model on the web, though not with any specific device in mind (and it only includes mainstream media, no blogs). That would be the next step. Premium papers like the Times or The Washington Post might become the HBOs and Showtimes of this text-ripping scheme — pay a little extra and you get the entire electronic edition uploaded daily to your tpod.
 As for the device, well, the Sony Librie has had reasonable success in Japan and will soon be released in the States. The Librie is incredibly light and uses an “e-ink” display that is reflective like paper (i.e. it can be read in bright sunlight), and can run through 10,000 page views on four triple-A batteries.
As for the device, well, the Sony Librie has had reasonable success in Japan and will soon be released in the States. The Librie is incredibly light and uses an “e-ink” display that is reflective like paper (i.e. it can be read in bright sunlight), and can run through 10,000 page views on four triple-A batteries.
The disadvantages: it’s only black-and-white and has no internet connectivity. It also doesn’t seem to be geared for pulling syndicated text. Bob brought one back from Japan. It’s nice and light, and the e-ink screen is surprisingly sharp. But all in all, it’s not quite there yet.
There’s always the do-it-yourself approach. The Voyager Company in Japan has developed a program called T-Time (the image at the top is from their site) that helps you drag and drop text from the web into an elegant ebook format configureable for a wide range of mobile devices: phones, PDAs, ipods, handheld video games, camcorders, you name it. This demo (in Japanese, but you’ll get the idea) demonstrates how it works.
Presumably, you would also read novels on your text pod. I personally would be loathe to give up paper here, unless it was a novel that had to be read electronically because it was multimedia, or networked, or something like that. But for syndicated text — periodicals, serials, essays — I can definitely see the appeal of this theoretical device. I think it’s something people would use.
news and blogs to live under one roof at yahoo!
Yahoo’s revamped news search will present news and blogs side by side on the same page. In addition, the site will feature related images from Flickr, the social photo-sharing site that Yahoo purchased earlier this year, as well as user-contributed links from My Web (a feature that allows you to save and store web pages, and share them with others).
As before, the front news page will promote only stories from mainstream media sources, while the blog-news combo appears on a second-tier page that you arrive at when you conduct a specific search, or click for more details or more stories. No doubt, this was done, at least in part, to mollify angry news outlets who will likely call foul for making hard news share space with blogs. Still, the webscape has changed. All but the most cursory glance at the headlines will yield a richly confusing array of mainstream and grassroots sources.
(story, Yahoo Search Blog)
(thoughtful analysis from Tim Porter)