
 From Dan Cohen’s excellent Digital Humanities Blog comes a discussion of the Wikipedia story that Cohen claims no one seems to be writing about — namely, the question of why Google and Yahoo give so much free server space and bandwith to Wikipedia. Cohen points out that there’s more going on here than just the open source ethos of these tech companies: in fact, the two companies are becoming increasingly dependent on Wikipedia as a resource, both as something to repackage for commercial use (in sites such as Answers.com), and as a major component in the programming of search algorithms. Cohen writes:
From Dan Cohen’s excellent Digital Humanities Blog comes a discussion of the Wikipedia story that Cohen claims no one seems to be writing about — namely, the question of why Google and Yahoo give so much free server space and bandwith to Wikipedia. Cohen points out that there’s more going on here than just the open source ethos of these tech companies: in fact, the two companies are becoming increasingly dependent on Wikipedia as a resource, both as something to repackage for commercial use (in sites such as Answers.com), and as a major component in the programming of search algorithms. Cohen writes:
Let me provide a brief example that I hope will show the value of having such a free resource when you are trying to scan, sort, and mine enormous corpora of text. Let’s say you have a billion unstructured, untagged, unsorted documents related to the American presidency in the last twenty years. How would you differentiate between documents that were about George H. W. Bush (Sr.) and George W. Bush (Jr.)? This is a tough information retrieval problem because both presidents are often referred to as just “George Bush” or “Bush.” Using data-mining algorithms such as Yahoo’s remarkable Term Extraction service, you could pull out of the Wikipedia entries for the two Bushes the most common words and phrases that were likely to show up in documents about each (e.g., “Berlin Wall” and “Barbara” vs. “September 11” and “Laura”). You would still run into some disambiguation problems (“Saddam Hussein,” “Iraq,” “Dick Cheney” would show up a lot for both), but this method is actually quite a powerful start to document categorization.
Cohen’s observation is a valuable reminder that all of the discussion of Wikipedia’s accuracy and usefulness as an academic tool is really only skimming the surface of how and why the open-souce encyclopedia is reshaping the way knowledge is made and accessed. Ultimately, the question of whether or not Wikipedia should be used in the classroom might be less important than whether — or how — it is used in the boardroom, by companies whose function is to repackage, reorganize and return “the people’s knowledge” back to the people at a tidy profit.
Author Archives: lisa lynch
phone photo of london underground nominated for time best photo; photo agency claims credit for creative commons work
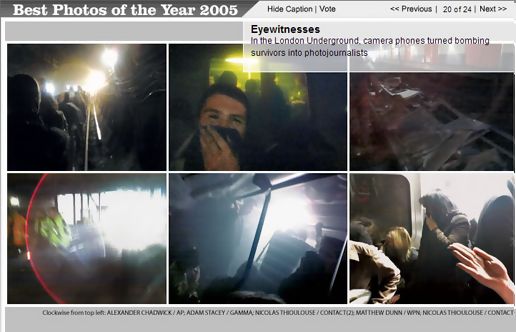
Moblog co-founder Alfie Dennen is furious that the photo agency Gamma has claimed credit for a well-known photo of last summer’s London subway bombing –first circulated on Moblog under a Creative Commons liscence — that was chosen for Time’s annual Best Photo contest. Dennen and others in the blogosphere are hoping that photographer Adam Stacey might take legal action against Gamma for what seems to be a breach of copyright.
We at the Institute are still trying to figure out what to make of this. Like everyone else who has been observing the increasing popularity of the Creative Commons license, we’ve been wondering when and how the license will be tested in court. However, this might not be the best possible test case. On one hand, it seems to be a somewhat imperious “claiming” of a photo widely celebrated for being produced by a citizen journalist who was committed to its free circulation. One the other hand, it seems unclear whether Dennen and/or Stacey are correct in their assertion that the CC license that was used really prohibits Gamma from attaching their name to the photo.
The photo in question, a shot of gasping passengers evacuating the London Underground in the moments after last summer’s bombing (in the image above, it’s the second photo clockwise), was snapped by Stacey using the camera on his cellphone. Time’s nomination of the photo most likely reflects the fact that the photo itself — and Stacey — became something of a media phenomenon in the weeks following the bombing. The image was posted on Moblog about 15 minutes after the bombing, and then widely circulated in both print and online media venues. Stacey subsequently appeared on NPR’s All Things Considered, and the photo was heralded as a signpost that citizen journalism had come into its own.
While writing about the photo’s appearance in Time, Dennen noticed that Time had credited the photo to Adam Stacey/Gamma instead of Adam Stacey/Creative Commons. According to Dennen, Stacey had been contacted by Gamma and had turned down their offer to distribute the photo, so the attribution came as an unpleasant shock. He claims that the license chosen by Stacey clearly indicates that the photo be given Creative Commons attribution. But is this really clear? The photo is attributed to Stacey, but not to Creative Commons: does this create a grey area? The license does allow commercial use of Stacey’s photo, so if Gamma was making a profit off the image, that would be legal as well.
Dennen writes on his weblog that he contacted Gamma for an explanation, arguing that after Stacey told the agency that he wanted to distribute the photo through Creative Commons, they should have understood that they could use it, but not claim it as their own. Gamma responded in an email that, “[we] had access to this pix on the web as well as anyone, therefore we downloaded it and released it under Gamma credit as all agencies did or could have done since there was no special requirement regarding the credit.” They also claimed that in their conversation with Stacey, Creative Commons never came up, and that a “more complete answer” to the reason for the attribution would be available after January 3rd, when the agent who spoke with Stacey returned from Christmas vacation.
Until then, it’s difficult to say whether Gamma’s claim of credit for the photo is accidental or deliberate disregard. Dennen also says that he’s contacting Time to urge them to issue a correction, but he hasn’t gotten a response yet. I’ll follow this story as it develops.
bookcrossing.com and the future of the book
 I came across an an interesting overview piece on the future of the book in Global Politician, an online magazine that largely focuses on reporting underreported global issue stories. The author of the piece, economist and political consultant Sam Vaknin, covers much of the terrain we usually cover here at the Institute, but he also make an interesting point about how the online book-swapping collective Bookcrossing has been turning paper books into “networked books” over the past four years. Vaknin writes:
I came across an an interesting overview piece on the future of the book in Global Politician, an online magazine that largely focuses on reporting underreported global issue stories. The author of the piece, economist and political consultant Sam Vaknin, covers much of the terrain we usually cover here at the Institute, but he also make an interesting point about how the online book-swapping collective Bookcrossing has been turning paper books into “networked books” over the past four years. Vaknin writes:
Members of the BookCrossing.com community register their books in a central database, obtain a BCID (BookCrossing ID Number) and then give the book to someone, or simply leave it lying around to be found. The volume’s successive owners provide BookCrossing with their coordinates. This innocuous model subverts the legal concept of ownership and transforms the book from a passive, inert object into a catalyst of human interactions. In other words, it returns the book to its origins: a dialog-provoking time capsule.
I appreciate the fact that Vaknin draws attention to the ways in which books can be conceptually transformed by ventures such as BookCrossing even while they remain physically unchanged. Currently, there are only about half a million BookCrossing members, making the phenemenon somewhat less popular than podcasting, but given that most BookCrossing members are serious readers — and highly international — the movement is still noteworthy.
wikipedia and ‘alien logic:’ the debate gets spiritual
If you like Mitchell Stephen’s book-blog about the history of atheism, you might want to compare Mitchell’s approach to that of “The Long Tail,” a book-blog written by Chris Anderson of Wired Magazine. Like Stephens, Anderson is trying to work out his ideas for a future book online: his book looks at the technology-driven atomizaton of our economy and culture, a phenomenon Anderson (and Wired) doesn’t seem particularly troubled by.
On December 18, Anderson wrote a post about what he saw as the real reason people are uncomfortable with Wikipedia: according to Anderson, we’re unable to reconcile with the “alien logic” of probabilistic and emergent systems, which produce “correct” answers on the macro-scale because “they are statistically optimized to excel over time and large numbers” — even though no one is really minding the store.
On one hand, Anderson’s been saying what I (and lots of other people) have been saying repeatedly over the past few weeks: acknowledge that sometimes Wikipedia gets things wrong, but also pay attention to the overwhelming number of times the open-source encyclopedia gets things right. At the same time, I’m not comfortable with Anderson’s suggestion that we can’t “wrap our heads around” the essential rightness of probabalistic engines — especially when he compares this to not being able to wrap our heads around probibalistic systems. This call for greater faith in the algorithm also troubles Nicholas Carr, who responds agnostically:
Maybe it’s just the Christmas season, but all this talk of omniscience and inscrutability and the insufficiency of our mammalian brains brings to mind the classic explanation for why God’s ways remain mysterious to mere mortals: “Man’s finite mind is incapable of comprehending the infinite mind of God.” Chris presents the web’s alien intelligence as something of a secular godhead, a higher power beyond human understanding… I confess: I’m an unbeliever. My mammalian mind remains mired in the earthly muck of doubt. It’s not that I think Chris is wrong about the workings of “probabilistic systems.” I’m sure he’s right. Where I have a problem is in his implicit trust that the optimization of the system, the achievement of the mathematical perfection of the macroscale, is something to be desired….Might not this statistical optimization of “value” at the macroscale be a recipe for mediocrity at the microscale – the scale, it’s worth remembering, that defines our own individual lives and the culture that surrounds us?
Carr’s point is well-taken: what is valuable about Wikipedia to many of us is not that it is an engine for self-regulation, but that it allows individual human beings to come together to create a shared knowledge resource. Anderson’s call for faith in the system is swinging the pendulum too far in the other direction: while other defenders of Wikipedia have pointed out ways to tinker with the encyclopedia’s human interface, Anderson implies that the human interface — at the individual level — doesn’t quite matter. I don’t find this particularly conforting: in fact, this idea seems much scarier than Seigenthaler’s warning that Wikipedia is a playground for “volunteer vandals.”
the future of the book(store), circa 1899 and 2005
Leafing through an 1899 issue of the literary magazine The Dial, I came across an article called “The Distribution of Books” which resonated with the present moment at several uncanny junctures, and got me thinking about the evolving relationship between publishers, libraries, bookstores, and Google Book Search — thoughts which themselves evolved after a conversation with a writer from Pages magazine about the future of bookstores.
“The Distribution of Books” focused mainly on changes in the way books were marketed and distributed, warning that bookstores might go out of business if they failed to change their own business practices in response. “Once more the plaint of the bookseller is heard in the land,” lamented the author, “and one would be indeed stony-hearted who could view his condition without concern.”

According to “The Distribution of Books,” what should have been the privileged domain of the bookseller was being eroded at the century’s end by the book sales of “the great dealers in miscellaneous merchandise.” The article was referring to the department stores that sold books at a loss in order to lure in customers: a bit less than a century later, critics would make the same claims about Amazon, that great dealer in miscellaneous merchandise now celebrating its tenth anniversary. “The Distribution of Books” also complains of the direct marketing practices of publishers who attempted to market to readers directly. This past year, similar complaints were made after Random House joined Scholastic and Simon and Schuster this year in establishing a direct-sale online presence.
Of course, 2005 is not 1899, and this is what makes the Dial piece so startling in its familiarity: in 1899, after all, the distinction between publisher and bookseller was much fresher than now. Hybrid merchant/tradesman who printed, marketed and distributed books at the same time had been the norm for a much longer interval than the shop owner who ordered books from a variety of different publishing houses. In this sense, the publisher’s “new” practice of selling books directly was in fact a modification of bookselling practices that predated the specialized bookshop. Ultimately, the Dial piece is less about the demise of the bookseller than about the imagined demise of a relatively recent phenomenon — the specialized book seller with an investment in promoting the culture of books generally rather than the work of a specific author or publisher.
This tension between specialization and generalization also revealed itself in the article’s most indignant passage, in which the author expressed outrage over the idea that libraries might themselves get involved in bookselling. According to the Dial, bookstore owners had been subjected to:
an onslaught so unexpected and so startling it left [them] gasping for breath — [a suggestion] made a few months ago by librarian Dewey, who calmly proposed that the public libraries throughout the country should be book-selling as well as book-circulating agencies… Booksellers have always looked askance at public libraries, not understanding how they create an appetite for reading that is sure in the end to redound to the bookseller’s advantage, but their suspicious fears never anticipated the explosion in their camp of such a bombshell as this.
After delivering the “bombshell,” the author goes on to reassure the reader that Dewey’s suggestion (yes, that would be Melvil Dewey, inventor of the Dewey Decimal System) could never be taken seriously in America: such a venture on the part of the nation’s libraries would represent a socialistic entangling of the spheres of government and industry. Books sold by libraries would be sold without an eye to profit, conjectured the author, and publishing —-and perhaps the notion of the private sector itself — would collapse. “If the state or the municipality were to go into the business of selling books at cost, what should prevent it from doing the like with groceries?”
While the Dial piece made me think about the ways in which the perceived “new” threats to today’s bookstores might not be so new, it also made me consider how Dewey’s proposal might emerge in modified form in the digital era. While present-day libraries haven’t been proposing the sale of books, they certainly are planning to get into the business of marketing and distribution, as the World Digital Library attests. They are also proposing, as Librarian of Congress librarian James Billington has said, a shift toward significant partnerships with for-profit businesses which have (for various reasons) serious economic stakes in sifting through digital materials. And, as Ben noted a few weeks ago, libraries themselves have been using various strategies from online retailers to catalog and present information.
Just as libraries are starting to embrace the private sector, many bookstores are heading in the other direction: driven to the verge of extinction by poor profits, they are reinventing themselves as nonprofits that serve a valuable social and cultural function. Sure, books are still for sale, but the real “value” of a bookstore is now lies not in its merchandise, but in the intellectual or cultural community it fosters: in that respect, some bookstores are thus akin to the subscription libraries of the past.
Is it so impossible to imagine a future in which one walks into a digital distribution center, orders a latte, and uses an Amazon-type search engine to pull up the ebook that can be read at one’s reading station after the requisite number of ads have flashed on the screen? Is this a library? Is this a bookstore? Does it matter? Should it?
mass culture vs technoculture?
 It’s the end of the year, and thus time for the jeremiads. In a December 18 Los Angeles Times article, Reed Johnson warns that 2005 was the year when “mass culture” — by which Johnson seemed to mean mass media generally — gave way to a consumer-driven techno-cultural revolution. According to Johnson:
It’s the end of the year, and thus time for the jeremiads. In a December 18 Los Angeles Times article, Reed Johnson warns that 2005 was the year when “mass culture” — by which Johnson seemed to mean mass media generally — gave way to a consumer-driven techno-cultural revolution. According to Johnson:
This was the year in which Hollywood, despite surging DVD and overseas sales, spent the summer brooding over its blockbuster shortage, and panic swept the newspaper biz as circulation at some large dailies went into free fall. Consumers, on the other hand, couldn’t have been more blissed out as they sampled an explosion of information outlets and entertainment options: cutting-edge music they could download off websites into their iPods and take with them to the beach or the mall; customized newcasts delivered straight to their Palm Pilots; TiVo-edited, commercial-free programs plucked from a zillion cable channels. The old mass culture suddenly looked pokey and quaint. By contrast, the emerging 21st century mass technoculture of podcasting, video blogging, the Google Zeitgeist list and “social networking software” that links people on the basis of shared interest in, say, Puerto Rican reggaeton bands seems democratic, consumer-driven, user-friendly, enlightened, opinionated, streamlined and sexy.
Or so it seems, Johnson continues: before we celebrate too much, we need to remember the difference between consumers and citizens. We are technoconsumers, not technocitizens, and as we celebrate our possibilites, we forget that “much of the supposedly independent and free-spirited techno-culture is being engineered (or rapidly acquired) by a handful of media and technology leviathans: News Corp., Apple, Microsoft, Yahoo, and Google, the budding General Motors of the Information Age.”
 I hadn’t thought of Google as the GM of the Information Age. I’m not at all sure, actually, that the analogy works, given the different ways in which GM and Google leverage the US economy — fifty years hence, Google plant closures won’t be decimating middle America. But I’m very much behind Johnson’s call for more attention to media consolidation in the age of convergence. Soon, it’s going to be time for the Columbia Journalism Review to add the leviathans listed above to its Who Owns What page, which enables users to track the ownership of most old media products, but currently comes up short in tracking new media. Actually, they should consider updating it as of tomorrow, when the final details of Google’s billion dollar deal for five percent of AOL are made public.
I hadn’t thought of Google as the GM of the Information Age. I’m not at all sure, actually, that the analogy works, given the different ways in which GM and Google leverage the US economy — fifty years hence, Google plant closures won’t be decimating middle America. But I’m very much behind Johnson’s call for more attention to media consolidation in the age of convergence. Soon, it’s going to be time for the Columbia Journalism Review to add the leviathans listed above to its Who Owns What page, which enables users to track the ownership of most old media products, but currently comes up short in tracking new media. Actually, they should consider updating it as of tomorrow, when the final details of Google’s billion dollar deal for five percent of AOL are made public.
librivox — free public domain books read aloud by volunteers
Just read a Dec. 16th Wired article about a Canadian Hugh McGuire’s brilliant new venture Librivox. Librivox is creating and distributing free audiobooks by asking volunteers to create audio files of works of literature in the public domain. The files are hosted on the Internet Archive and are available in MP3 and OGG formats.
 Thus far, Librivox — which has only been up for a few months — has recorded about 30 titles, relying on dozens of volunteers. The website promotes the project as the “acoustical liberation of the public domain” and claims that the ultimate goal is to liberate all public domain works of literature. For now, titles cataloged on the website include L Frank Baum’s The Wizard of Oz, Joseph Conrad’s The Secret Agent and the U.S. Constitution.
Thus far, Librivox — which has only been up for a few months — has recorded about 30 titles, relying on dozens of volunteers. The website promotes the project as the “acoustical liberation of the public domain” and claims that the ultimate goal is to liberate all public domain works of literature. For now, titles cataloged on the website include L Frank Baum’s The Wizard of Oz, Joseph Conrad’s The Secret Agent and the U.S. Constitution.
Using Librivox couldn’t be easier: clicking on an entry will bring you to a screen which allows you to select a Wikipedia entry on the book in question, the e-Gutenberg file of the book, an alternate Zip file of the book, and the Librivox audio version, available chapter by chapter with the names of each volunteer reader noted prominently next to the chapter information.
I listened to parts of about a half-dozen book chapters to get a sense of the quality of the recordings, and I was impressed. The volunteers have obviously chosen books they are passionate about, and the recordings are lively, quite clear and easy to listen to. As a regular audiobook listener, I was struck by the fact that while most literary audiobooks are read by authors who tend to work hard at conveying a sense of character, the Librivox selections seemed to convey, more than anything, the reader’s passion for the text itself; ie, for the written word. Here at the Institute we’ve been spending a fair amount of time trying to figure out when a book loses it’s book-ness, and I’d argue that while some audiobooks blur the boundary between book and performance, the Librivox books remind us that a book reduced to a stream of digitally produced sound can still be very much a book.
The site’s definitely worth a visit, and, if you’ve got a decent voice and a few spare hours, there’s information about how to become a volunteer reader yourself. And finally, don’t miss the list of other audiolit projects on the lower right-hand corner of the homepage: there are many voices out there, reading many books — including Japanese Classical Literature For Bedtime, if you’re so inclined.
watching wikipedia watch
In an interview in CNET today, Daniel Brandt of Wikipedia Watch — the man who tracked down Brian Chase, the author of the false biography of John Seigenthaler on Wikipedia — details the process he used to track Chase down. I found it an interesting reality check on the idea of online anonymity. I was also a bit nonplussed by the fact that Brandt created a phony identity for himself in order to discover who had created a fake version of the real Seigenthaler. According to Brandt:
All I had was the IP address and the date and timestamp, and the various databases said it was a BellSouth DSL account in Nashville. I started playing with the search engines and using different tools to try to see if I could find out more about that IP address. They wouldn’t respond to trace router pings, which means that they were blocked at a firewall, probably at BellSouth…But very strangely, there was a server on the IP address. You almost never see that, since at most companies, your browsers and your servers are on different IP addresses. Only a very small company that didn’t know what it was doing would have that kind of arrangement. I put in the IP address directly, and then it comes back and said, “Welcome to Rush Delivery.” It didn’t occur to me for about 30 minutes that maybe that was the name of a business in Nashville. Sure enough they had a one-page Web site. So the next day I sent them a fax. [they didn’t respond, and] The next night, I got the idea of sending a phony e-mail, I mean an e-mail under a phony name, phony account. When they responded, sure enough, the originating IP address matched the one that was in Seigenthaler’s column.
Overall, I’m still having mixed feelings about Brandt’s “bust” of Brian Chase — mostly because of the way the event has skewed discussion of Wikipedia, but partly because Chase’s outing seems to have damaged the hapless-seeming Chase much more than Seigenthaler had been damaged by the initial fake post. The CNET interview suggests that Brandt might also have some regrets about the fallout over Chase, though Brandt frames his concern as yet another critique of Wikipedia. Brandt claims he is uncomfortable about the fact that Chase has a Wikipedia biography, since “when this poor guy is trying to send out his resume,” employers will google him, find the Wikipedia entry, and refuse to hire him: since Wikipedia entries are not as ephemeral as news articles, he adds, the entry is actually “an invasion of privacy even more than getting your name in the newspaper.” This seems to be an odd bit of reasoning, since Brandt, after all, was the one who made Chase notorious.
When asked by the CNET interviewer how he would “fix” Wikipedia, Brandt maintained an emphasis on the idea that biographical entries are Wikipedia’s Achilles heel, an belief which is tied, perhaps, to his own reasons for taking Wikipedia to task — a prominent draft resister in the 1960s, Brandt discovered that his own Wikipedia post had links he considered unflattering. He explained to CNET that his first priority would be to “freeze” biographies on the site which had been checked for accuracy:
I would go and take all the biographical articles on living persons and take them out of the publicly editable Wikipedia and put them in a sandbox that’s only open to registered users. That keeps out all spiders and scrapers. And then you work on all these biographies and get them up to snuff and then put them back in the main Wikipedia for public access but lock them so they cannot be edited. If you need to add more information, you go through the process again. I know that’s a drastic change in ideology because Wikipedia’s ideology says that the more tweaks you get from the masses, the better and better the article gets and that quantity leads to improved quality irrevocably. Their position is that the Seigenthaler thing just slipped through the crack. Well, I don’t buy that because they don’t know how many other Seigenthaler situations are lurking out there.
“Seigenthaler situations.” This term could either come in to use as a term to refer to the dubious accuracy of an online post — or, alternately, to refer to a phobic response to open-source knowledge construction. Time will tell.
Meanwhile, in the pro-Wikipedia world, an article in the Chronicle of Higher Education today notes that a group of Wikipedia fans have decided to try to create a Wikiversity, a learning center based on Wiki open-source principles. According to the Chronicle, “It’s not clear exactly how extensive Wikiversity would be. Some think it should serve only as a repository for educational materials; others think it should also play host to online courses; and still others want it to offer degrees.” I’m curious to see if anything like a Wikiversity could get off the group, and how it will address the tension around open-source knowledge that been foregrounded by the Wikipedia-bashing that has taken place over the past few weeks.
Finally, there’s a great defense of Wikipedia in Danah Boyd’s Apophenia. Among other things, Boyd writes:
We should be teaching our students how to interpret the materials they get on the web, not banning them from it. We should be correcting inaccuracies that we find rather than protesting the system. We have the knowledge to be able to do this, but all too often, we’re acting like elitist children. In this way, i believe academics are more likely to lose credibility than Wikipedia.
nature magazine says wikipedia about as accurate as encyclopedia brittanica
 A new and fairly authoritative voice has entered the Wikipedia debate: last week, staff members of the science magazine Nature read through a series of science articles in both Wikipedia and the Encyclopedia Britannica, and decided that Britannica — the “gold standard” of reference, as they put it — might not be that much more reliable (we did something similar, though less formal, a couple of months back — read the first comment). According to an article published today:
A new and fairly authoritative voice has entered the Wikipedia debate: last week, staff members of the science magazine Nature read through a series of science articles in both Wikipedia and the Encyclopedia Britannica, and decided that Britannica — the “gold standard” of reference, as they put it — might not be that much more reliable (we did something similar, though less formal, a couple of months back — read the first comment). According to an article published today:
Entries were chosen from the websites of Wikipedia and Encyclopaedia Britannica on a broad range of scientific disciplines and sent to a relevant expert for peer review. Each reviewer examined the entry on a single subject from the two encyclopaedias; they were not told which article came from which encyclopaedia. A total of 42 usable reviews were returned out of 50 sent out, and were then examined by Nature’s news team. Only eight serious errors, such as misinterpretations of important concepts, were detected in the pairs of articles reviewed, four from each encyclopaedia. But reviewers also found many factual errors, omissions or misleading statements: 162 and 123 in Wikipedia and Britannica, respectively.
It’s interesting to see Nature coming to the defense of Wikipedia at the same time that so many academics in the humanities and social science have spoken out against it: it suggests that the open source culture of academic science has led to a greater tolerance for Wikipedia in the scientific community. Nature’s reviewers were not entirely thrilled with Wikipidia: for example, they found the Britannica articles to be much more well-written and readable. But they also noted that Britannica’s chief problem is the time and effort it takes for the editorial department to update material as a scientific field evolves or changes: Wikipedia updates often occur practically in real time.
One not-so-suprising fact unearthed by Nature’s staffers is that the scientific community contained about twice as many Wikipedia users as Wikipedia authors. The best way to ensure that the science in Wikipedia is sound, the magazine argued, is for scientists to commit to writing about what they know.
no more shrek figures with your fries: Disney wants to digitize and serialize the happy meal giveaway
 A Dec 6th article in New Scientist notes that patents filed by Disney last April reveal plans to drip-feed entertainment into the handheld video players of children eating in McDonalds. The patent suggests that instead of giving out toys with Happy Meals, McDonalds might provide installments of a Disney tale: the child would only get the full story by coming back to the restaurant a number of times to collect all the installments. Here’s some text from the patent:
A Dec 6th article in New Scientist notes that patents filed by Disney last April reveal plans to drip-feed entertainment into the handheld video players of children eating in McDonalds. The patent suggests that instead of giving out toys with Happy Meals, McDonalds might provide installments of a Disney tale: the child would only get the full story by coming back to the restaurant a number of times to collect all the installments. Here’s some text from the patent:
…the downloading of small sections or parts of content can be spread out over a long period of time, e.g., 5 days. Each time a different part of the content, such as a movie, is downloaded, until the entire movie is accumulated. Thus, as a promotional program with a venue, such as McDonald’s.RTM. restaurant, a video, video game, new character for a game, etc., can be sent to the portable media player through a wireless internet connection… as an alternative to giving out toys with Happy Meals or some other promotion. The foregoing may be accomplished each time the player is within range of a Wi Fi or other wireless access point. The reward for eating at a restaurant, for example, could be the automatic downloading of a segment of a movie or the like…

Hmm. Some small issues to be worked through here — like identifying that elusive target market of parents willing to hand their child a video ipod while he or she is eating a cheeseburger and fries. But if this is a real direction for the future, what might it portend? Will Disney tales distributed on the installment plan capture the interest of children as much as small plastic figurines representing the main characters of their latest Disney experience? And what’s ultimately better for the development of a young imagination, a small plastic Shrek or five minutes from a mini-Shrek video (the choice of “neither” is not an option here)? Can we imagine such a distribution method returning us to the nineteenth-century serialization manial prompted by Dicken’s chapter-by-chapter account of the death of Little Nell?
image: the death of little nell from Dicken’s The Old Curiosity Shop, 1840