

The ever-innovative University of Pennsylvania library is piloting a new social bookmarking system (like del.icio.us or CiteULike), in which the Penn community can tag resources and catalog items within its library system, as well as general sites from around the web. There’s also the option of grouping links thematically into “projects,” which reminds me of Amazon’s “listmania,” where readers compile public book lists on specific topics to guide other customers. It’s very exciting to see a library experimenting with folksonomies: exploring how top-down classification systems can productively collide with grassroots organization.
Monthly Archives: June 2006
wikipedia in the times
Wikipedia is on the front page of the New York Times today, presumably for the first time. The article surveys recent changes to the site’s governance structure, most significantly the decision to allow administrators (community leaders nominated by their peers) to freeze edits on controversial pages. These “protection” and “semi-protection” measures have been criticized by some as being against the spirit of Wikipedia, but have generally been embraced as a necessary step in the growth of a collective endeavor that has become increasingly vast and increasingly scrutinized.
Browsing through a few of the protected articles — pages that have been temporarily frozen to allow time for hot disputes to cool down — I was totally floored by the complexity of the negotiations that inform the construction of a page on, say, the Moscow Metro. I attempted to penetrate the dense “talk” page for this temporarily frozen article, and it appears that the dispute centered around the arcane question of whether numbers of train lines should be listed to the left of a color-coded route table. Tempers flared and things apparently reached an impasse, so the article was frozen on June 10th by its administrator — a user by the name of Ezhiki (Russian for hedgehogs), who appears to be taking a break from her editing duties until the 20th (whether it is in connection to the recent metro war is unclear).
Look at Ezhiki’s profile page and you’ll see a column of her qualifications and ranks stacked neatly like merit badges. Little rotating star .gifs denote awards of distinction bestowed by the Wikipedia community. A row of tiny flag thumbnails at the bottom tells you where in the world Ezhiki has traveled. There’s something touching about the page’s cub scout aesthetic, and the obvious idealism with which it is infused. Many have criticized Wikipedia for a “hive mind” mentality, but here I see a smart individual with distinct talents (and a level head for conflict management), who has pitched herself into a collective effort for the greater good. And all this obsessive, financially uncompensated striving — all the heated “edit wars” and “revert wars” — for the production of something as prosaic as an encyclopedia, a mere doormat on the threshold of real knowledge.
But reworking the doormat is a project of massive proportions, and one that carries great political and social significance. Who should produce these basic knowledge resources and how should the kernel of knowledge be managed? These are the questions that Wikipedia has advanced to the front page of the newspaper of record. The mention of WIkipedia on the front of the Times signifies its crucial place in the cultural moment, and provides much-needed balance to the usual focus in the news on giant commercial players like Google and Microsoft. In a time of uncontrolled media oligopoly and efforts by powerful interests to mould the decentralized structure of the Internet into a more efficient architecture of profit, Wikipedia is using the new technologies to fuel a great humanistic enterprise. Wikipedia has taken the model of open source software and applied it to general knowledge. The addition of a few governance measures only serves to demonstrate the increasing maturity of the project.
mapping books
Gutenkarte is an effort to map books by MetaCarta. The website takes text from books in Project Gutenberg, searches them for the appearance of place names, and plots them on a map of the world using their own GeoParser API, creating an astonishing visualization of the world described in a text. Here, for example, is a map of Edward Gibbon’s Decline and Fall of the Roman Empire:
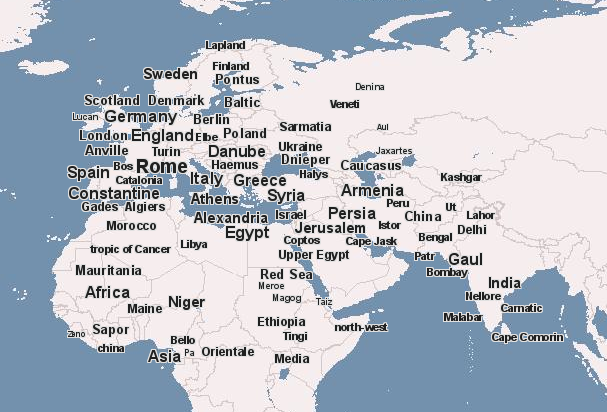
(Click on the picture to view the live map.) It’s not perfect yet: note that “china” is in the Ivory Coast, and “Asia” seems to be located just off the coast of Cameroon. But the map does give an immediate sense of the range of Gibbon’s book: in this case, the extent of the Roman world. The project is still in its infancy: eventually, users will be able to correct mistakes.
Gutenkarte suggests ways of looking at texts not dissimilar from that of Franco Moretti, who in last year’s Graphs, Maps, Trees: Abstract Models for Literary History (discussed by The Valve here) discussed how making maps of places represented in literature could afford a new way of discussing texts. Here, for example, is a map he constructed of Parisian love affairs in the novel, demonstrating that lovers were usually separated by the Seine:
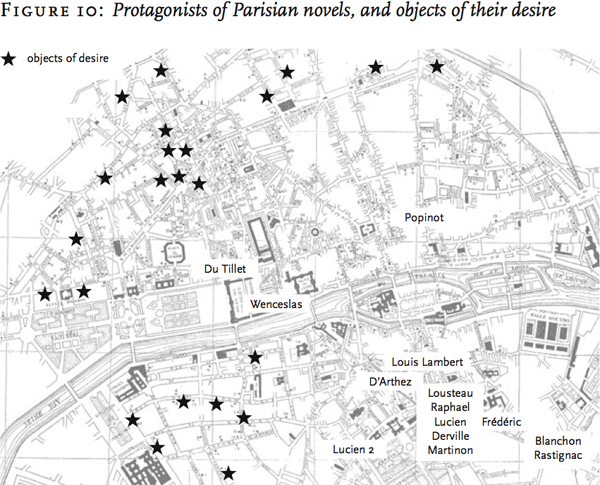
(from the “Maps” chapter, online here if you have university access to the New Left Review.) Moretti constructed his maps by hand, with the help of grad student labor; it will be interesting to see if Gutenkarte will make this sort of visualization accessible to all.
the music world steps into the net neutrality debate
I’m still getting my head wrapped about this tune by the BroadBand. Written and performed by Kay Hanley (former lead singer of Letters to Cleo), Jill Sobule (“I Kissed a Girl” with one-time MTV staple video starring Fabio), and Michelle Lewis, “God Save the Internet” is another step in making the issues surrounding net neutrality more public. Perhaps my favorite lyric is “Jesus wouldn’t mess with our Internet.” Cheeky lyrics aside, the download page does include links to resources for the inspired activist, including a provocative editorial from allhiphop.com on why the African American community should be concerned about net neutrality. The telecommunication lobby is financing an well-funded campaign to implement the pro-telecom polices it supports. It is still unclear how effective the net neutrality movement will be, but it is slowly expanding beyond legal scholars into the general cultural sphere. The increasing involvement from the pop culture world, be it alt-rock or hip hop, will extend the movement’s reach to more people and encourage more discourse. All this will hopefully result in a balanced and fair approach to telecommunications policy and legislation.
an important guide on filmmaking and fair use
 “The Documentary Filmmakers’ Statement of Best Practices in Fair Use,” by the Center for Social Media at American University is another work in support of fair-use practices to go along with the graphic novel “Bound By Law” and the policy report “Will Fair Use Survive?“.
“The Documentary Filmmakers’ Statement of Best Practices in Fair Use,” by the Center for Social Media at American University is another work in support of fair-use practices to go along with the graphic novel “Bound By Law” and the policy report “Will Fair Use Survive?“.
“Will Fair Use Survive” (which Jesse previously discussed) takes a deeper policy analysis approach. “Bound By Law” (also reviewed by me) uses an accessible tact to raise awareness in this area. Whereas, “The Statement of Best Practice” is geared towards the actual use of copyrighted material under fair use by practicing documentary filmmakers. It is an important compliment to the other works because the current confusion over claiming fair use has resulted in a chilling effect which stops filmmakers from pursuing projects which require (legal) fair use claims. This document give them specific guidelines on when and how they can make fair use claims. Assisting filmmakers in their use of fair use will help shift the norms of documentary filmmaking and eventually make these claims easier to defend. This guide was funded by the Rockefeller Foundation, the MacArthur Foundation and Grantmakers in Film and Electronic Media.
reflections on the hyperlinked.society conference
Last week, Dan and I attended the hyperlinked.society conference hosted at the University of Pennsylvania’s Annenberg School of Communication. An impressive collection of panelists and audience members gathered to discuss issues that are emerging as we place more value onto hyperlinks. Here are a few reflections on what was covered at the one day conference.
David Weinberger made a good framing statement when he noted that links are the architecture of the web. Through technologies, such as Google Page Rank, linking is not only a conduit to information, but it is also now a way of adding value to another site. People noted the tension between not wanting to link to a site they disagreed with (for example, an opposing political site) which would increase its value in ranking criteria and with the idea that linking to other ideas a fundamental purpose of the web. Currently, links are binary, on or off. Context for the link is given by textual descriptions given around the link. (For example, I like to read this blog.) Many suggestions were offered to give the link context, through color, icon or tags within the code of the link to show agreement or disagreement with the contents of the link. Jesse discusses overlapping issues in his recent post on the semantic wiki. Standards can be developed to achieve this, however we must be take care to anticipate the gaming of any new ways of linking. Otherwise, these new links will became another casualty of the web, as seen with through the misuse of meta tags. Meta tags were key words included in HTML code of pages to assist search engines on determining the contains of the site. However, massive misuse of these keywords rendered meta-tags useless, and Google was one of the first, if not the first, search engine to completely ignore meta-tags. Similar gaming is bound to occur with adding layers of meaning to links, and must be considered carefully in the creation of new web conventions, lest these links will join meta-tags as footnote in HTML reference books.
Another shift I observed, was an increase in citing real quantifiable data be it from both market and academic research on people’s web use. As Saul Hansell pointed out, the data which is able to be collected is only a slice of reality, however these snapshots are still useful in gaining understand how people are using new media. The work of Lada Adamic (whose work we like to refer to in ifbook) on mapping the communication between political blogs will be increasingly important in understand online relationships. She also showed more recent work on representing how information flows and spreads through the blogosphere.
Some of the work by presented by mapmakers and cartographers showed examples of using data to describe voting patterns as well as cyberspace. Meaningful maps of cyberspace are particularly difficult to create because as Martin Dodge noted, we want to compress hundreds of thousands of dimensions into two or three dimensions. Maps are representations of data, at first they were purely geographic, but eventually things such as weather patterns and economic trends have been overlaid onto their geographic locations. In the context of hyperlinks, I look forward to using these digital maps as an interface to the data underlaying these representations. Beyond voting patterns (and privacy issues aside,) linking these maps to deeper information on related demographic and socio-economic data and trends seems like the logical next step.
I was also surprised at what was not mentioned or barely mentioned. Net neutrality and copyright were each only raised once, each time by an audience members’ question. Ethan Zuckerman gave an interesting anecdote that the Global Voices project became an advocate for the Creative Commons license because they found it to be a powerful tool to support their effort to support bloggers in the developing world. Further, in the final panel of moderators, they mentioned that privacy, policy, tracking received less attention then expected. On that note, I’ll close with two questions that lingered in my mind, as I left Philadelphia for home. I hope that they will be addressed in the near future, as the importance of hyperlinking grows in our lives.
1. How will we deal with link rot and their ephemeral nature of link?
Broken links and archiving links will become increasing important as the number of links along with our dependence on them grow in parallel.
2. Who owns our links?
As we put more and more of ourselves, our relationships and our links on commercial websites, it is important to reflect upon what are the implications when we are at the same time giving ownership of these links over to Yahoo via flickr and News Corp via my.space.
microsoft enlists big libraries but won’t push copyright envelope
In a significant challenge to Google, Microsoft has struck deals with the University of California (all ten campuses) and the University of Toronto to incorporate their vast library collections – nearly 50 million books in all – into Windows Live Book Search. However, a majority of these books won’t be eligible for inclusion in MS’s database. As a member of the decidedly cautious Open Content Alliance, Windows Live will restrict its scanning operations to books either clearly in the public domain or expressly submitted by publishers, leaving out the huge percentage of volumes in those libraries (if it’s at all like the Google five, we’re talking 75%) that are in copyright but out of print. Despite my deep reservations about Google’s ascendancy, they deserve credit for taking a much bolder stand on fair use, working to repair a major market failure by rescuing works from copyright purgatory. Although uploading libraries into a commercial search enclosure is an ambiguous sort of rescue.
a bone-chilling message to academics who dare to become PUBLIC intellectuals
Juan Cole is a distinguished professor of middle eastern studies at the University of Michigan. Juan Cole is also the author of the extremely influential blog, Informed Comment which tens of thousands of people rely on for up-to-the-minute news and analysis of what is happening in Iraq and in the middle east more generally. It was recently announced that Yale University rejected Cole’s nomination for a professorship in middle eastern studies, even after he had been approved by both the history and sociology departments. As might be expected there is considerable outcry, particularly from the progressive press and blogosphere criticizing Yale for caving in to what seems to have been a well-orchestrated campaign against Cole by the hard-line pro-Israel forces in the U.S.
Most of the stuff I’ve read so far seems to concentrate on taking Yale’s administration to task for their spinelessness. While this criticism seems well-founded, I think there is a bigger issue that isn’t being addressed. The conservatives didn’t go after Cole simply because of his political ideas. There are most likely people already in Yale’s Middle Eastern studies dept. with politics more radical than Cole’s. They went after him because his blog, which reaches out to a broad general audience is read by tens of thousands and ensures that his ideas have a force in the world. Juan once told me that he’s lucky if he sells 500 copies of his scholarly books. His blog however ranks in the Technorati 50 and through his blog he has also picked up influential gigs in Salon and NPR.
Yale’s action will have a bone-chilling effect on academic bloggers. Before the Cole/Yale affair it was only non-tenured professors who feared that speaking out publicly in blogs might have a negative impact on their careers. Now with Yale’s refusal to approve the recommendation of its academic departments — even those with tenure must realize that if they dare to go outside the bounds of the academy to take up the responsibilities of public intellectuals, that the path to career advancement may be severely threatened.
We should have defended Juan Cole more vigorously, right from the beginning of the right-wing smear against him. Let’s remember that the next time a progressive academic blogger gets tarred by those who are afraid of her ideas.
smarter links for a better wikipedia
As Wikipedia continues its evolution, smaller and smaller pieces of its infrastructure come up for improvement. The latest piece to step forward to undergo enhancement: the link. “Computer scientists at the University of Karlsruhe in Germany have developed modifications to Wikipedia’s underlying software that would let editors add extra meaning to the links between pages of the encyclopaedia.” (full article) While this particular idea isn’t totally new (at least one previous attempt has been made: platypuswiki), SemanticWiki is using a high profile digital celebrity, which brings media attention and momentum.
What’s happening here is that under the Wikipedia skin, the SemanticWiki uses an extra bit of syntax in the link markup to inject machine readable information. A normal link in wikipedia is coded like this [link to a wiki page] or [http://www.someothersite.com link to an outside page]. What more do you need? Well, if by “you” I mean humans, the answer is: not much. We can gather context from the surrounding text. But our computers get left out in the cold. They aren’t smart enough to understand the context of a link well enough to make semantic decisions with the form “this link is related to this page this way”. Even among search engine algorithms, where PageRank rules them all, PageRank counts all links as votes, which increase the linked page’s value. Even PageRank isn’t bright enough to understand that you might link to something to refute or denigrate its value. When we write, we rely on judgement by human readers to make sense of a link’s context and purpose. The researchers at Karlsruhe, on the other hand, are enabling machine comprehension by inserting that contextual meaning directly into the links.
SemanticWiki links look just like Wikipedia links, only slightly longer. They include info like
- categories: An article on Karlsruhe, a city in Germany, could be placed in the City Category by adding
[[Category: City]]to the page. - More significantly, you can add typed relationships.
Karlsruhe [[:is located in::Germany]]would show up as Karlsruhe is located in Germany (the : before is located in saves typing). Other examples: in the Washington D.C. article, you can add [[is capital of:: United States of America]]. The types of relationships (“is capital of”) can proliferate endlessly. - attributes, which specify simple properties related to the content of an article without creating a link to a new article. For example,
[[population:=3,396,990]]
Adding semantic information to links is a good idea, and hewing closely to the current Wikipedia syntax is a smart tactic. But here’s why I’m not more optimistic: this solution combines the messiness of tagging with the bother of writing machine readable syntax. This combo reminds me of a great Simpsons quote, where Homer says, “Nuts and gum, together at last!” Tagging and semantic are not complementary functions – tagging was invented to put humans first, to relieve our fuzzy brains from the mechanical strictures of machine readable categorization; writing relationships in a machine readable format puts the machine squarely in front. It requires the proliferation of wikipedia type articles to explain each of the typed relationships and property names, which can quickly become unmaintainable by humans, exacerbating the very problem it’s trying to solve.
But perhaps I am underestimating the power of the network. Maybe the dedication of the Wikipedia community can overcome those intractible systemic problems. Through the quiet work of the gardeners who sleeplessly tend their alphanumeric plots, the fact-checkers and passers-by, maybe the SemanticWiki will sprout links with both human and computer sensible meanings. It’s feasible that the size of the network will self-generate consensus on the typology and terminology for links. And it’s likely that if Wikipedia does it, it won’t be long before semantic linking makes its way into the rest of the web in some fashion. If this is a success, I can foresee the semantic web becoming a reality, finally bursting forth from the SemanticWiki seed.
UPDATE:
I left off the part about how humans benefit from SemanticWiki type links. Obviously this better be good for something other than bringing our computers up to a second grade reading level. It should enable computers to do what they do best: sort through massive piles of information in milliseconds.
How can I search, using semantic annotations? – It is possible to search for the entered information in two differnt ways. On the one hand, one can enter inline queries in articles. The results of these queries are then inserted into the article instead of the query. On the other hand, one can use a basic search form, which also allows you to do some nice things, such as picture search and basic wildcard search.
For example, if I wanted to write an article on Acting in Boston, I might want a list of all the actors who were born in Boston. How would I do this now? I would count on the network to maintain a list of Bostonian thespians. But with SemanticWiki I can just add this: <ask>[[Category:Actor]] [[born in::Boston]], which will replace the inline query with the desired list of actors.
To do a more straightforward search I would go to the basic search page. If I had any questions about Berlin, I would enter it into the Subject field. SemanticWiki would return a list of short sentences where Berlin is the subject.
But this semantic functionality is limited to simple constructions and nouns—it is not well suited for concepts like 'politics,' or 'vacation'. One other point: SemanticWiki relationships are bounded by the size of the wiki. Yes, digital encyclopedias will eventually cover a wide range of human knowledge, but never all. In the end, SemanticWiki promises a digital network populated by better links, but it will take the cooperation of the vast human network to build it up.
e-paper takes another step forward

With each news item of flexible display technology, I get the feeling that we are getting closer to the wide spread use of e-paper. The latest product to appear is Seiko Epson’s QXGA e-paper, which was recently introduced at a symposium given by the Society for Information Display. Even from the small jpeg, the text looks sharp and easy to read. Although e-paper will not replace all paper, I’m looking forward to the day I can store all my computer manuals on e-paper. Computer manuals are voluminous and quickly become outdated with each new upgrade. I typically repeatedly use only a few pages of the entire manual. All these reasons makes them a great candidate for e-paper. Perhaps, the best benefit is that I can use the new found shelf space for print books where I value the vessel as much as the content.
Via Engadget