There’s been an explosion of creative tinkering since the BBC opened up its API (applications programming interface) last month. An API is a window into a site’s code and content allowing techie types to build new applications with BBC material. It’s really worth going over to the BBC Backstage blog to take a look at the first batch of prototypes and demos. The majority are clever splicings of BBC data – news, traffic reports, images etc. – with Google Maps (everyone’s favorite lately), not unlike chicagocrime.org. Other notable examples: an RSS feed of BBC complaints; a feature that allows you to tag articles and read tags left by other readers; and a nice “tag soup” visualization of financial news.
Correction: A reader kindly pointed out that BBC Backstage hasn’t actually released APIs yet (though they intend to soon). The projects I’ve referenced use BBC feeds, or have scraped content directly from the BBC site. APIs are to follow soon (more info here). When they do, the scaping process will become much cleaner. For now, the BBC welcomes projects that “use our stuff to build your stuff” the rough-and-tumble way, and is happy to showcase them on the Backstage site.
The API is becoming a powerful tool for creative reinvention of the web. Back in April, I wrote about Dan Gillmor’s piece on “Web 3.0”.. Web 1.0 was the early web, a place you went to read – a series of interconnected brochures. Web 2.0 is the “read-write” web – it’s a place you go to interact. Web 3.0 is where we start weaving the disparate pieces into new forms. APIs let you do this. You take one application and design a new front end that shows your point of view. Or you take two applications and mix them together, creating something new and illuminating. Right now, Web 2.0 is pretty well in place. The tools for self-expression and interaction are pretty accessible – email, chat, blogs, etc. But the weaving tools required for 3.0 are available only to advanced users. We’ll see if that changes.
Here are grabs from four of the map prototypes at BBC Backstage:
Traffic Maps:
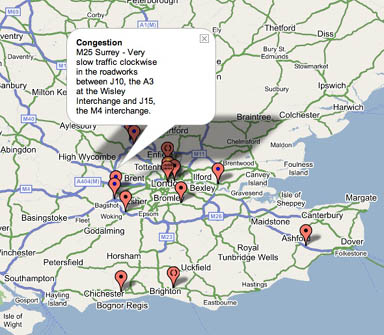
Map of BBC London Jam Cams:
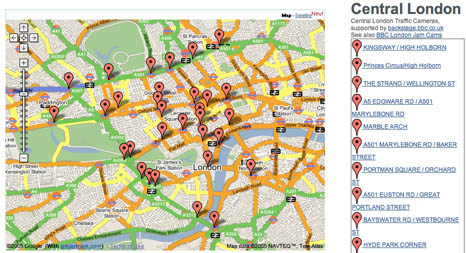
Photo Mapping:
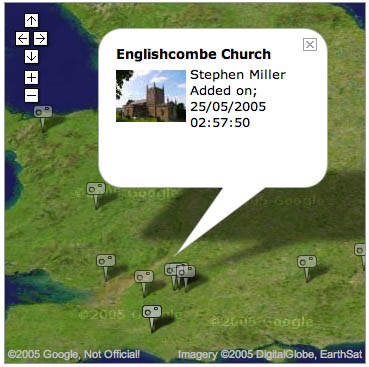
Map of the News:
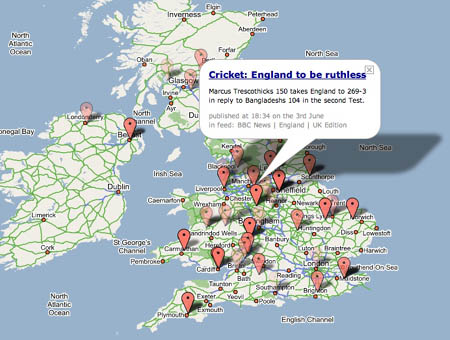
For more analysis, check out this article on O’Reilly Radar.