
question posed by John Brockman and answered by predictable (but interesting) members of the digerati. definitely worth browsing.
is Google good for history?
Following are Dan Cohen’s prepared remarks for a talk at the American Historical Association Annual Meeting, on January 7, 2010, in San Diego. The panel was entitled “Is Google Good for History?” and also featured talks by Paul Duguid of the University of California, Berkeley and Brandon Badger of Google Books. This is cross-posted from Dan’s blog
Is Google good for history? Of course it is. We historians are searchers and sifters of evidence. Google is probably the most powerful tool in human history for doing just that. It has constructed a deceptively simple way to scan billions of documents instantaneously, and it has spent hundreds of millions of dollars of its own money to allow us to read millions of books in our pajamas. Good? How about Great?
But then we historians, like other humanities scholars, are natural-born critics. We can find fault with virtually anything. And this disposition is unsurprisingly exacerbated when a large company, consisting mostly of better-paid graduates from the other side of campus, muscles into our turf. Had Google spent hundreds of millions of dollars to build the Widener Library at Harvard, surely we would have complained about all those steps up to the front entrance.
Partly out of fear and partly out of envy, it’s easy to take shots at Google. While it seems that an obsessive book about Google comes out every other week, where are the volumes of criticism of ProQuest or Elsevier or other large information companies that serve the academic market in troubling ways? These companies, which also provide search services and digital scans, charge universities exorbitant amounts for the privilege of access. They leech money out of library budgets every year that could be going to other, more productive uses.
Google, on the other hand, has given us Google Scholar, Google Books, newspaper archives, and more, often besting commercial offerings while being freely accessible. In this bigger picture, away from the myopic obsession with the Biggest Tech Company of the Moment (remember similar diatribes against IBM, Microsoft?), Google has been very good for history and historians, and one can only hope that they continue to exert pressure on those who provide costly alternatives.
Of course, like many others who feel a special bond with books and our cultural heritage, I wish that the Google Books project was not under the control of a private entity. For years I have called for a public project, or at least a university consortium, to scan books on the scale Google is attempting. I’m envious of France’s recent announcement to spend a billion dollars on public scanning. In addition, the Center for History and New Media has a strong relationship with the Internet Archive to put content in a non-profit environment that will maximize its utility and distribution and make that content truly free, in all senses of the word. I would much rather see Google’s books at the Internet Archive or the Library of Congress. There is some hope that HathiTrust will be this non-Google champion, but they are still relying mostly on Google’s scans. The likelihood of a publicly funded scanning project in the age of Tea Party reactionaries is slim.
* * *
Long-time readers of my blog know that I have not pulled punches when it comes to Google. To this day the biggest spike in readership on my blog was when, very early in Google’s book scanning project, I casually posted a scan of a human hand I found while looking at an edition of Plato. The post ended up on Digg, and since then it has been one of the many examples used by Google’s detractors to show a lack of quality in their library project.
Let’s discuss the quality issues for a moment, since it is one point of obsession within the academy, an obsession I feel is slightly misplaced. Of course Google has some poor scans–as the saying goes, haste makes waste–but I’ve yet to see a scientific survey of the overall percentage of pages that are unreadable or missing (surely a miniscule fraction in my viewing of scores of Victorian books). Regarding metadata errors, as Jon Orwant of Google Books has noted, when you are dealing with a trillion pieces of metadata, who are likely to have millions of errors in need of correction. Let us also not pretend the bibliographical world beyond Google is perfect. Many of the metadata problems with Google Books come from library partners and others outside of Google.
Moreover, Google likely has remedies for many of these inadequacies. Google is constantly improving its OCR and metadata correction capabilities, often in clever ways. For instance, it recently acquired the reCAPTCHA system from Carnegie Mellon, which uses unwitting humans who are logging into online services to transcribe particularly hard or smudged words from old books. They have added a feedback mechanism for users to report poor scans. Truly bad books can be rescanned or replaced by other libraries’ versions. I find myself nonplussed by quality complaints about Google Books that have engineering solutions. That’s what Google does; it solves engineering problems very well.
Indeed, we should recognize (and not without criticism, as I will note momentarily) that at its heart, Google Books is the outcome, like so many things at Google, of a engineering challenge and a series of mathematical problems: How can you scan tens of million books in a decade? It’s easy to say they should do a better job and get all the details right, but if you do the calculations with those key variables, as I assume Brandon and his team have done, you’ll probably see that getting a nearly perfect library scanning project would take a hundred years rather than ten. (That might be a perfectly fine trade-off, but that’s a different argument or a different project.) As in OCR, getting from 99% to 99.9% accuracy would probably take an order of magnitude longer and be an order of magnitude more expensive. That’s the trade-off they have decided to make, and as a company interested in search, where near-100% accuracy is unnecessary, and considering the possibilities for iterating toward perfection from an imperfect first version, it must have been an easy decision to make.
* * *
Google Books is incredibly useful, even with the flaws. Although I was trained at places with large research libraries of Google Books scale, I’m now at an institution that is far more typical of higher ed, with a mere million volumes and few rare works. At places like Mason, Google Books is a savior, enabling research that could once only be done if you got into the right places. I regularly have students discover new topics to study and write about through searches on Google Books. You can only imagine how historical researchers and all students and scholars feel in even less privileged places. Despite its flaws, it will be the the source of much historical scholarship, from around the globe, over the coming decades. It is a tremendous leveler of access to historical resources.
Google is also good for history in that it challenges age-old assumptions about the way we have done history. Before the dawn of massive digitization projects and their equally important indices, we necessarily had to pick and choose from a sea of analog documents. All of that searching and sifting we did, and the particular documents and evidence we chose to write on, were–let’s admit it–prone to many errors. Read it all, we were told in graduate school. But who ever does? We sift through large archives based on intuition; sometime we even find important evidence by sheer luck. We have sometimes made mountains out of molehills because, well, we only have time to sift through molehills, not mountains. Regardless of our technique, we always leave something out; in an analog world we have rarely been comprehensive.
This widespread problem of anecdotal history, as I have called it, will only get worse. As more documents are scanned and go online, many works of historical scholarship will be exposed as flimsy and haphazard. The existence of modern search technology should push us to improve historical research. It should tell us that our analog, necessarily partial methods have had hidden from us the potential of taking a more comprehensive view, aided by less capricious retrieval mechanisms which, despite what detractors might say, are often more objective than leafing rapidly through paper folios on a time-delimited jaunt to an archive.
In addition, listening to Google may open up new avenues of exploring the past. In my book Equations from God I argued that mathematics was generally considered a divine language in 1800 but was “secularized” in the nineteenth century. Part of my evidence was that mathematical treatises, which often contained religious language in the early nineteenth century, lost such language by the end of the century. By necessity, researching in the pre-Google Books era, my textual evidence was limited–I could only read a certain number of treatises and chose to focus (I’m sure this will sound familiar) on the writings of high-profile mathematicians. The vastness of Google Books for the first time presents the opportunity to do a more comprehensive scan of Victorian mathematical writing for evidence of religious language. This holds true for many historical research projects.
So Google has provided us not only with free research riches but also with a helpful direct challenge to our research methods, for which we should be grateful. Is Google good for history? Of course it is.
* * *
But does that mean that we cannot provide constructive criticism of Google, to make it the best it can be, especially for historians? Of course not. I would like to focus on one serious issue that ripples through many parts of Google Books.
For a company that is a champion of openness, Google remains strangely closed when it comes to Google Books. Google Books seems to operate in ways that are very different from other Google properties, where Google aims to give it all away. For instance, I cannot understand why Google doesn’t make it easier for historians such as myself, who want to do technical analyses of historical books, to download them en masse more easily. If it wanted to, Google could make a portal to download all public domain books tomorrow. I’ve heard the excuses from Googlers: But we’ve spent millions to digitize these books! We’re not going to just give them away! Well, Google has also spent millions on software projects such as Android, Wave, Chrome OS, and the Chrome browser, and they are giving those away. Google’s hesitance with regard to its books project shows that openness goes only so far at Google. I suppose we should understand that; Google is a company, not public library. But that’s not the philanthropic aura they cast around Google Books at its inception or even today, in dramatic op-eds touting the social benefit of Google Books.
In short, complaining about the quality of Google’s scans distracts us from a much larger problem with Google Books. The real problem–especially for those in the digital humanities but increasingly for many others–is that Google Books is only open in the read-a-book-in-my-pajamas way. To be sure, you can download PDFs of many public domain books. But they make it difficult to download the OCRed text from multiple public domain books-what you would need for more sophisticated historical research. And when we move beyond the public domain, Google has pushed for a troubling, restrictive regime for millions of so-called “orphan” books.
I would like to see a settlement that offers greater, not lesser access to those works, in addition to greater availability of what Cliff Lynch has called “computational access” to Google Books, a higher level of access that is less about reading a page image on your computer than applying digital tools to many pages or books at one time to create new knowledge and understanding. This is partially promised in the Google Books settlement, in the form of text-mining research centers, but those centers will be behind a velvet rope and I suspect the casual historian will be unlikely to ever use them. Google has elaborate APIs, or application programming interfaces, for most of its services, yet only the most superficial access to Google Books.
For a company that thrives on openness and the empowerment of users and software developers, Google Books is a puzzlement. With much fanfare, Google has recently launched–evidently out of internal agitation–what it calls a “Data Liberation Front,” to ensure portability of data and openness throughout Google. On dataliberation.org, the website for the front, these Googlers list 25 Google projects and how to maximize their portability and openness–virtually all of the main services at Google. Sadly, Google Books is nowhere to be seen, even though it also includes user-created data, such as the My Library feature, not to mention all of the data–that is, books–that we have all paid for with our tax dollars and tuition. So while the Che Guevaras put up their revolutionary fist on one side of the Googleplex, their colleagues on the other side are working with a circumscribed group of authors and publishers to place messy restrictions onto large swaths of our cultural heritage through a settlement that few in the academy support.
Jon Orwant and Dan Clancy and Brandon Badger have done an admirable job explaining much of the internal process of Google Books. But it still feels removed and alien in way that other Google efforts are not. That is partly because they are lawyered up, and thus hamstrung from responding to some questions academics have, or from instituting more liberal policies and features. The same chutzpah that would lead a company to digitize entire libraries also led it to go too far with in-copyright books, leading to a breakdown with authors and publishers and the flawed settlement we have in front of us today.
We should remember that the reason we are in a settlement now is that Google didn’t have enough chutzpah to take the higher, tougher road–a direct challenge in the courts, the court of public opinion, or the Congress to the intellectual property regime that governs many books and makes them difficult to bring online, even though their authors and publishers are long gone. While Google regularly uses its power to alter markets radically, it has been uncharacteristically meek in attacking head-on this intellectual property tower and its powerful corporate defenders. Had Google taken a stronger stance, historians would have likely been fully behind their efforts, since we too face the annoyances that unbalanced copyright law places on our pedagogical and scholarly use of textual, visual, audio, and video evidence.
I would much rather have historians and Google to work together. While Google as a research tool challenges our traditional historical methods, historians may very well have the ability to challenge and make better what Google does. Historical and humanistic questions are often at the high end of complexity among the engineering challenges Google faces, similar to and even beyond, for instance, machine translation, and Google engineers might learn a great deal from our scholarly practice. Google’s algorithms have been optimized over the last decade to search through the hyperlinked documents of the Web. But those same algorithms falter when faced with the odd challenges of change over centuries and the alienness of the past and old books and documents that historians examine daily.
Because Google Books is the product of engineers, with tremendous talent in computer science but less sense of the history of the book or the book as an object rather than bits, it founders in many respects. Google still has no decent sense of how to rank search results in humanities corpora. Bibliometrics and text mining work poorly on these sources (as opposed to, say, the highly structured scientific papers Google Scholar specializes in). Studying how professional historians rank and sort primary and seconary sources might tell Google a lot, which it could use in turn to help scholars.
Ultimately, the interesting question might not be, Is Google good for history? It might be: Is history good for Google? To both questions, my answer is: Yes.
the zeitgeist checks in to the consumer electronics show
the never-ending stream of announcements of tablets and dedicated e-book devices from CES is a clear indicator that e-reading is coming of age. the open publishing lab at RIT is keeping track of all the relevant developments here.
the other side of the long tail
Jace Clayton quotes an article from The Economist:
A lot of the people who read a bestselling novel, for example, do not read much other fiction. By contrast, the audience for an obscure novel is largely composed of people who read a lot. That means the least popular books are judged by people who have the highest standards, while the most popular are judged by people who literally do not know any better. An American who read just one book this year was disproportionately likely to have read “The Lost Symbol”, by Dan Brown. He almost certainly liked it.
It’s worth paying a look at the original article, “A World of Hits”, which originally came out last November. It’s been borne out since: my holiday and post-holiday discussions of the media were dominated by Avatar, to the exclusion of almost anything else. A lot of people wanted to talk about Avatar, and there’s a fair amount to discuss there: how pretty it is, how it works as mass spectacle, the film’s deeply muddled politics, how ecology and religion are connected. What stands out to me is how rarely this happens any more. It’s not that I don’t have, for example, film people to talk about films with, or movie people to talk about movies with, but there’s always some element of singing to the choir in this. An example: the record I liked the most in 2009 was the favorite record of plenty of other people, but didn’t merit a mention in the New York Times. I don’t think this is necessarily because the Times has especially bad music coverage; there’s simply a lot of media happening, and it’s impossible for any publication to cover everything in depth. The sheer ubiquity of Avatar changed how it could be discussed: something so big can cut across our individual interest groups, enabling broader conversations.
But the inevitable question arises: what does it mean if the only cultural object that everyone can talk about costs $300 million? Producers aren’t going to give $300 million to anyone who has a story that they need to discuss. The great power of the written word – why the word “book” continues to mean so much to us – is its fundamental democracy: that anyone literate can set pen to paper and write something. Technology, the truism goes, is politically neutral; but I wonder if this can be true in a practical sense when the tools of expression are so expensive.
smart thinking from Mitch Ratcliffe
Mitch Ratcliffe posted this very smart piece yesterday and gave permission to cross-post it on if:book.
How to create new reading experiences profitably
Concluding my summary of my recent presentation to a publishing industry group, begun here and continued here, we turn to the question of what to do to revitalize the publishing opportunity.
I wrote a lot about the idea of exploding the limitations of the book in the last installment. Getting beyond the covers. Turning from a distribution model to a reader-centric model. It’s simple to argue that change is needed and to say what needs changing. Here, I offer a few specific ideas about lines of research and development that I would like to see begun by publishers, who, if they wish to remain viable–let alone profitable–must undertake immediately. The change in book publishing will happen at a faster pace than the collapse of newspaper and music publishing did, making a collective effort at research and publication of the results for all to discuss and use, critical during the next 18 months. Think open sourcing the strategy, so that a thousand innovations can bloom.
Making books into e-books is not the challenge facing publishers and authors today. In fact, thinking in terms of merely translating text to a different display interface completely misses the problem of creating a new reading experience. Books have served well as, and will continue to be, containers for moving textual and visual information between places and across generations. They work. They won’t stop working. But when moving to a digital environment, books need to be conceived with an eye firmly set on the interactions that the text/content will inspire. Those interactions happen between the author and work, the reader and the work, the author and reader, among readers and between the work and various services, none of which exist today in e-books, that connect works to one another and readers in the community of one book with those in other book-worlds.
Just as with the Web, where value has emerged out of the connection of documents by publishers and readers–the Web is egalitarian in its connectivity, but still has some hierarchical features in its publishing technologies–books must be conceived of not just as a single work, but a collection of work (chapters, notes, illustrations, even video, if you’re thinking of a “vook”) that must be able to interact internally and with other works with which it can communicate over an IP network. This is not simply the use of social media within the book, though that’s a definite benefit, but making the book accessible for use as a medium of communication. Most communities emerge long after the initial idea that catalyzes them is first published.
These communications “hooks” revolve around traditional bibliographic practices, such as indexing and pagination for making references to a particular location in a book useful, as well as new functionality, such as building meta-books that combine the original text with readers’ notes and annotations, providing verification of texts’ authenticity and completeness, curation (in the sense that, if I buy a book today and invest of myself in it the resulting “version” of the book will be available to others as a public or private publication so that, for instance, I can leave a library to my kids and they can pass it along to their children) and preservation.
Think about how many versions of previously published books, going all the way back to Greek times, when books were sold on scrolls in stalls at Athens, have been lost. We treasure new discoveries of an author’s work. In a time of information abundance, however, we still dismiss all the other contributions that make a book a vital cultural artifact. Instead, we need to recognize that capturing the discussions around a book, providing access (with privacy intact) to the trails that readers have followed on their own or in discussions with others to new interpretations and uses for a text, and the myriad commentaries and marginalia that have made a book important to its readers is the new source of infinite value that can be provided as the experience we call “reading.” Tomorrow’s great literary discovery may not be an original work by a famous author, but a commentary or satire written by others in response to a book (as the many “…with sea monsters and vampires” books out there are beginning to demonstrate today). Community or, for lack of a better way of putting it, collaboration, is the source of emergent value in information. Without people talking about the ideas in a book, the book goes nowhere. This is why Cory Doctorow and Seth Godin’s advice about giving away free e-books makes so much sense, up to a point. Just turning a free ebook into the sale of a paper book leaves so much uninvented value on the table that, frankly, readers will never realize to get if someone doesn’t roll the experience up into a useful service.
The interaction of all the different “versions” of a book is what publishers can facilitate for enhanced revenues. This could also be accomplished by virtually anyone with a budget necessary to support a large community. The fascinating thing about the networked world, of course, is that small communities are what thrive, some growing large, so that anyone could become a “publisher” by growing a small community into a large or multi-book community.
Publishers can, though they may not be needed to, provide the connectivity or, at least, the “switchboards” that connect books. The BookServer project recently announced by The Internet Archive takes only one of several necessary steps toward this vision, though it is an important one: If realized, it will provide searchable indices and access to purchase or borrow any book for consumption in paper or a digital device. That’s big. It’s a huge project, but it leaves out all the content and value added to books by the public, by authors who release new editions (which need to be connected, so that readers want to understand the changes made between editions), and, more widely, the cultural echoes of a work that enhance the enjoyment and importance attributed to a work.
What needs to exist beside the BookServer project is something I would describe as the Infinite Edition Project. This would build on the universal index of books, but add the following features:
Word and phrase-level search access to books, with pagination intact;
A universal pagination of a book based upon a definitive edition or editions, so that the books’ readers can connect through the text from different editions based on a curated mapping of the texts (this would yield one ISBN per book that, coupled with various nascent text indexing standards, could produce an index of a title across media);
Synchronization of bookmarks, notes and highlights across copies of a book;
A reader’s copy of each book that supported full annotation indexing, allowing any reader to markup and comment on any part of a book–the reader’s copy becomes another version of the definitive edition;
An authenticated sharing mechanism that blends reader’s copies of a book based on sharing permissions and, this is key, the ability to sell a text and the annotations separately, with the original author sharing value with annotators;
The ability to pass a book along to someone, including future generations–here, we see where a publisher could sell many copies of their books based on their promise to keep reader’s copies intact and available forever, or a lifetime;
An authentication protocol that validates the content of a book (or a reader’s copy), providing an “audit trail” for attribution of ideas–both authors and creative readers, who would be on a level playing field with authors in this scenario, would benefit, even if the rewards were just social capital and intellectual credit;
Finally, Infinite Edition, by providing a flourishing structure for author-reader and inter-generational collaboration, could be supported by a variety of business models.
One of the notions that everyone, readers and publishers included, have to get over is the idea of a universal format. Text these days is something you store but not something that is useful without metadata and application-layer services. Infinite Edition, as the illustration above shows, is a Web services-based concept that allows the text to move across devices and formats. It would include an API for synchronizing a reader’s copy of a book, as well as for publishers or authors to update or combine versions.
Done right, an Infinite Edition API would let a Kindle user share notes with a Nook user and with a community that was reading the book online; if, at some point, a new version of the book were to be printed, publishers could, with permission, augment the book with contributions of readers. Therein lies a defensible value-added service that, at the same time, is not designed to prevent access to books–it’s time to flip the whole notion of protecting texts on its head and talk about how to augment and extend texts. As I have written elsewhere over the years, this is a feature cryptographic technology is made to solve, but without the stupidity of DRM.
Granted, access to a book would still be on terms laid out by the seller (author, publisher or distributor, such as Amazon, which could sell the text with Kindle access included through its own secure access point to the Infinite Edition Web service) however, it would become an “open” useful document once in the owner’s hands. And all “owners” would be able to do much with their books, including share them and their annotations. Transactions would become a positive event, a way for readers to tap into added services around a book they enjoy.
Publishers must lead this charge, as I wrote last time, because distributors are not focused on the content of books, just the price. A smart publisher will not chase the latest format, instead she will emphasize the quality of the books offered to the market and the wealth of services those books make accessible to customers. This means many additive generations of development will be required of tool makers and device designers who want to capitalize on the functionality embedded in a well-indexed, socially enabled book. It will prevent the wasteful re-ripping of the same content into myriad formats in order to be merely accessible to different reader devices. And the publishers who do invent these services will find distributors as willing as ever to sell them, because a revived revenue model is attractive to everyone.
ePUB would be a fine foundation for an Infinite Edition project. So would plain text with solid pagination metadata. In the end, though, what the page is–paper or digital–will not matter as much as what is on the page. Losing sight of the value proposition in publishing, thinking that the packaging matters more than the content to be distributed, is what has nearly destroyed newspaper publishing. Content is king, but it is also coming from the masses and all those voices have individual value as great as the king. So, help pull these communities of thought and entertainment together to remain a vital contributor to your customers.
This raises the last challenge I presented during my talk. The entire world is moving to a market ideal of getting people what they want or need when they want or need it. Publishing is only one of many industries battling the complex strategic challenge of just-in-time composition of information or products for delivery to an empowered individual customer. This isn’t to say that it is any harder, nor any easier, to be a publisher today compared to say, a consumer electronics manufacturer or auto maker, only that the discipline to recognize what creates wonderful engaging experience is growing more important by the day.
As I intimated in the last posting, this presentation didn’t land me the job I was after. I came in second, which is a fine thing to do in such amazing times. Congratulations to Scott Lubeck, who was named today as executive director of the Book Industry Study Group. I have joined the BISG to be an activist member. I welcome contact from anyone wishing to discuss how the BISG or individual publishers can put these ideas into action, a little at a time or as a concerted effort to transform the marketplace.
the final cut
Julio Cortázar is one of those writers who is mentioned far more often than actually read; most people know that he wrote Hopscotch, a novel often mentioned as a precursor to hypertext fiction, or that he wrote the short stories that became Antonioni’s Blow Up and Godard’s Weekend. I’ve been belatedly making my way through his works over the past year, a pleasurable endeavor that I’d commend to anyone. For all the pleasure of his fiction, there’s a great deal that still bears consideration, especially in the English-speaking world where Cortázar hasn’t been widely read.
“We Love Glenda So Much” is the title story of one of Cortázar’s last collections of short stories, unfortunately out of print in English but easily available online. It’s a short Borgesian piece, told in the first person plural, and the premise is quickly related: the anonymous narrators idolize the movie star Glenda Garson and constitute a secret fan club for the most devoted fans who understand that her films are the only ones that matter. Things quickly escalate: though the members believe Glenda’s work to be perfection, they acknowledge that her films are perhaps not quite perfect. They laboriously gather up all the prints and re-edit them, creating not a director’s cut but a fans’ cut; the recut films are redistributed to an unsuspecting public; the differences between the new films and those released years before are chalked up to the vagaries of memory. All is well in the world; until Glenda decides to return from her retirement, at which point her fans lethally prevent her from sullying the perfection they have helped her achieve.
We Love Glenda So Much was originally published in 1980, just before the VCR became ubiquitous; it’s unclear when the story is set, but it presumes a world where all the copies of Glenda’s films can be gathered in by her hard-working (and conveniently rich) fans. Read 29 years later, it’s a remarkably different text: while fans are still reliably crazy, the way that the entertained interact with entertainers and that the media can be controlled – or not – has been transformed so much as to render Cortázar’s story a strange postcard from a forgotten land. Subcultures no longer exist in the way they did in the way Cortázar describes, even in the way they existed a dozen years ago, when it was necessary to hold fast to your own personal Glenda because of the investment, cultural or economic, that you’d made in loving her above everyone else. With ubiquitous media, everyone is free to be a dilettante.
More importantly, though, there’s been a shift in the center of control. When Cortázar wrote, the producers maintained control tightly; since then, media control has been dispersed to the point where it’s meaningless. (Cortázar’s language suggests a focus on this power shift: the members of the club that loves Glenda, a movement to seize power from Glenda’s producers, announce that think of themselves as a “nucleus,” suggesting a center of force, rather than a simple “club.”) It’s not hard to re-edit any movie you like to your pleasure; however, making your cut – even if you’re the director – the definitive cut is increasingly impossible. I’m not trying to argue that Cortázar was unperceptive and didn’t see the future coming; the story is a fabulation through and through, and I don’t imagine for a minute that Cortázar thought that what he was describing could happen in the real world. But I don’t think that it’s out of line to read Glenda, whose fans know better than her what she should do or not do, as a portrait of the artist himself. This story did appear in his penultimate collection of short stories, released four years before his death, and he may well have had posterity on his mind. Authorial intent is quickly dispensed with after the death of the author: the past year, for example, has seen new editions of the work of Hemingway, Carver, and Nabokov that would almost certainly violate authorial intent.
What makes “We Love Glenda So Much” interesting to me is how it points out this world of transformation that we’ve lived through. When looked at in terms of control, there’s also a distant echo of another transformation – Gutenberg’s invention of the printing press – which similarly dispersed control from the center to the masses. The generally accepted narrative of history has it that the coming of printing led directly to the massive societal upheaval that was the Protestant Reformation: the ability to quickly disperse texts led to a plurality of viewpoints. Gutenberg’s contemporaries aren’t noted for having had any idea how quickly their world would become utterly unrecognizable. Nostradamus, who might have, would arrive a generation later, just in time for the printing press to distribute his prophecies. One wonders how much of an idea we have now.
when we get what we want
It’s the shortest day of the year, New York is under a thick blanket of snow which will soon turn to slush, and it’s hard not to feel let down by the world: when the Democrats gut health care reform in the name of passing something; when Obama fails to accomplish anything meaningful in Copenhagen; as it becomes clear that the war in Afghanistan will soon be marching into its second decade; when bankers still gain million-dollar bonuses for doing, as far as one can tell, nothing useful; when Mexico City can legalize gay marriage before New York State. December, the end of the decade, both summon up the retrospective urge: to look back and wonder what was accomplished, what could have been accomplished. One feels more disappointed when it seems like something could have happened: a year ago it felt like Obama might be a light at the end of a decade-long tunnel.
It’s also the end of a year in which electronic books have received an amount of press that would have been unthinkable five years ago. At the same time, I find it hard to get as excited about anything recently: there’s been a great deal of hubbub about devices, but it seems clear that’s premature: any device will be obsolete in a year or so, when Apple rolls out its long-delayed tablet and a barrage of Google-powered devices follow in its wake. There’s a lot of publishing talk, but it’s not especially interesting for the would-be reader: publishers argue about the dates at which e-books come out relative to hardcovers, and whether to grant exclusive rights to a single distributer. It’s not particularly interesting, especially with the past five years in mind: in the current discussions, the book is simply a commodity, something to be passed off to consumers at the greatest profit the market will bear. (An analogous argument might be made about the social networking world, which seems to reach a logical conclusion in Blippy, a new social networking platform with the genius idea – albeit a recession too late – of replacing the arduousness of even Twitter-length communication with a record of one’s credit card purchases.) The argument could be made that electronic books have finally made it; executives make grand proclamations about how electronic sales will figure as such and such a percentage of future sales. Stephen Covey makes exclusive distribution deals with Amazon. Motoko Rich dutifully reports it all daily in The New York Times.
Part of my problem is personal. The technology world turns over so quickly: the five years that I’ve spent at the Institute is more than enough to make anyone feel wizened and elderly in the amnesiac new media world, if one didn’t come into it feeling that way. It becomes increasingly hard to find anything that seems new or interesting, let alone revelatory. And, as mentioned, it’s the end of the year; it’s dark, there’s a recession going on. But I’m not sure I’m alone in feeling that there’s been something of a longueur in the world of new or social media; I’ve had a number of conversations recently that come back around to this. A post by Whitney Trettien at diapsalmata beautifully identifies a related sort of frustration: the sense of being on the verge of a future that’s dragging its feet. Trettien begins her post with a triad of quotes on the imminence of a new digital reading experience, quotes that the unassuming reader might imagine to be from the present; they turn out to be from 1999.
* * * * *
Symptoms suggest a diagnosis; for a physician, I’ll suggest St. Teresa of Avila. Answered prayers, she noted, cause more tears than unanswered ones; Truman Capote would have put this on the cover of his unfinished novel about the unsated. At about the same time I was reading Capote, Courtney Love offered a more profane restatement: “I told you from the start just how this would end / when I get what I want I never want it again”. It’s a description that seems apt for the present: we’re living in a world of answered prayers. Obama restored order after eight years of misrule; millions of people are reading digitally from their iPhones and Kindles and whatever else they’re using.
Why tears then? By and large, the current raft of devices and software aren’t particularly innovative or attuned to how reading works; the reading experience itself isn’t substantially different than it was fifteen years ago, when Voyager was offering mass-market books on 3.5” disks for sale in bookstores, though the hardware’s much better. What’s different is the networked aspect: it’s now possible to get a huge number of books near instantaneously. Bored on a Virginia highway over Thanksgiving & feeling the need to re-read Edgar Allan Poe’s Narrative of A. Gordon Pym, I could nearly instantaneously (and without cost) download a copy to my iPhone. This is, it should be said, astonishing. The reading experience was terrible, but that’s beside the point: I could get the text (or an approximation thereof) almost as soon as I could imagine it. This is something new.
I’m interested in this sensation of immediate gratification: it’s one of the hallmarks of the present. Something similar is present when you can buy almost any piece of music from iTunes, or when you can choose from a plethora of movies to watch instantly on Netflix. In a weakened form, it’s the same experience as buying used books on Amazon, something I’m constantly doing: almost any book, no matter how out of print, will pop up on Amazon, and most can be yours for under $10 and inside a week. In all these cases: given enough capital and access to a network, the majority of our desires for media can be solved, increasingly instantaneously.
We don’t think about this very much, but this newfound ability to instantly satisfy our desires is actually a very strange development. So much of human development is a process of learning to deal with desires that are delayed or vexed; so much of the history of the book is a narrative of scarceness. In terms of the market, there was more demand than supply. The move to the digital has changed all that: the supply of a piece of digital content is, for most intents and purposes, infinite, and we find ourselves in a position where supply far exceeds demand. It isn’t just books where this is the case: it might be said that all electronic reading is in this position. If you have an even marginal amount of curiosity, there’s no end of content that could, given the time, be interesting.
But this change in values comes at a price: with this shift in values, it becomes very hard for us to know how to value content. We’re used to the arc of wanting – conceiving a desire, justifying it to ourselves, figuring out a way to get it, receiving it – that serves to convince ourselves of the importance of what we want. When that’s short-circuited, we’re left at a loss. In a previous end of the year piece, I used the example of the rescued Robinson Crusoe in Elizabeth Bishop’s “Crusoe in England”: he looks at his knife, the thing he once valued religiously, and finds that it’s become meaningless, just another knife. “The living soul,” he notes, “has dribbled away.” Maybe that’s where the book is now.
Raymond Aron, from Eighteen Lectures on the Industrial Society: “It is poverty that humanity, as a whole, still suffers from today. Poverty, defined simply by the lack of common measure between the desires of individuals and the means to satisfy them.”
* * * * *
I’ve been keeping a list this year of the books I’ve finished this year, from a need, I suppose, to keep some kind of record: if books make a man, keeping a list of ingredients might be useful, though for what I’m not sure, yet. I haven’t tallied up my year in reading yet, but I suspect I’ll wind up having read somewhere around a book every three days. (This isn’t particularly difficult if you have a typical New York commute and count on other people to read The New Yorker for you.) This seems desperate: a frantic attempt to stay abreast of a world that moves ever faster. There are more books on my lists of books to read than I have any reasonable chance of completing in my lifetime. This happens.
The most interesting reading experience of my year, however, wasn’t a book that I finished; rather, it was reading at a book that can’t be finished. I’ve been going to the monthly meetings of the New York Finnegans Wake reading group. I’m not, it should be said, the most religious of Joyceans; re-reading Ulysses a decade ago, I had an epiphany and suddenly understood what style meant, but if I had to make a list of my ten favorite writers I’m not entirely sure that Joyce would make the cut. It’s Proust that I go to when I want answers. But there’s something pleasing in the ritual aspect of the group reading of Finnegans Wake: feeling oneself a part of a community, a community devoted to something greater than oneself.
Each month the group makes its way through about two pages in two hours. Wine is drunk, everyone reads a bit of the text aloud. The group has been at this task for a very long time; the median age of the members is twice my age, and plenty of them have been at their reading since before I was born. Close reading is the only real way into Finnegans Wake. In a text so dense, the reader can only begin to understand by listening to others. Different readers find something different in it; some scrutinize the text silently, some sound out words for unvoiced puns, others argue their own idiosyncratic theories about the text. Digressions invariably arise and are followed. But when it works, it feels almost as if the text lifts off the page: out of the cacophony, you begin to hear how Joyce’s overlaid narratives resonate.
One arrives, finally, a bit closer to an understanding of the text. It’s something that’s only really possible through group reading: the individual reader can’t possibly know as much as the group – although something like the experience could certainly be asynchronously recreated if you had enough books and patience. But I’m most interested in the experience of reading this way: because in this community context, reading becomes something more than the interior experience that we usually think of reading as; it’s something entirely outside of the economic context (or even an academic one). I’ve never found anything quite like it on the Web, despite long residencies on a couple of literary mailing lists. Reading like this, one gets the sense that maybe one book might almost be enough for the rest of one’s life – provided, of course, that it was the right book. This, I think, might be one remedy we should be looking for if we’re trying to find way forward for reading: to think about reading as a matter of communal exchange rather than of commodity exchange.
commentpress 3.1
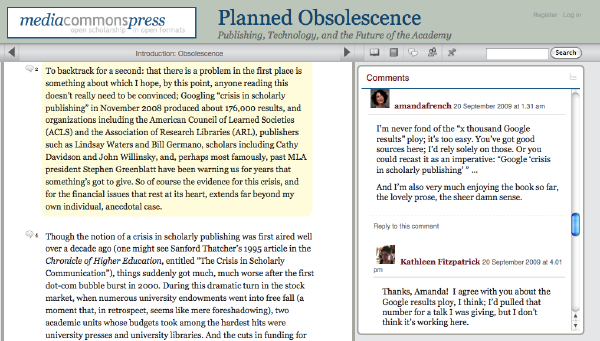
My colleagues and I are very happy to announce a completely re-vamped version of CommentPress. Available for download at /commentpress/.
If you want to see the new version in action, check out Kathleen Fitzpatrick’s Planned Obsolescence: Publishing, Technology, and the Future of the Academy.
The CD-Companion to Beethoven’s Ninth Symphony by Robert Winter
Robert Winter’s CD-Companion to Beethoven’s Ninth Symphony was published twenty years ago this week. As you look at this promo piece it’s important to realize that the target machine for this title was a Macintosh with a screen resolution of 640×400 and only two colors — black and white. This video dates from 1993.
two anniversaries
Just before Thanksgiving 1984, twenty-five years ago this week, The Criterion Collection was launched with the release of laserdisc editions Citizen Kane and King Kong.

In the video below critic Leonard Maltin introduces Criterion to his TV audience. Roger Smith who appears in the tape was one of Criterion’s co-founders. Ron Haver, who at the time was the film-curator at the LA County Museum of Art, made the first commentary track; a brilliant real-time introduction to the wonders of King Kong.
Although its since been changed, Criterion’s original logo from 1984 was based on the idea of a book turning into a disc. At the time it represented a conscious recognition that as microprocessors made their inevitable progression into all media devices, that the ways humans use and absorb media would change profoundly. The card below was distributed at the American Bookseller’s Convention (now the BEA) in June of 1984.


This week in 1988 also marks the publication of Voyager’s CD-Companion to Beethoven’s Ninth Symphony by Robert Winter — the title that launched the brief cd-rom era of the early 90s. In honor of that anniversary, beginning tomorrow and continuing through the end of the year, we’ll start posting promo pieces for a number of Voyager’s cd-roms.