
Cellphedia, a thesis project at the Interactive Telecommunications Program at NYU, is a user-generated encyclopedia composed of text message Q&A from cell phones – a kind of mobile, hyper-abbreviated Wikipedia. But unlike Wikipedia, Cellphedia entries are not open to editing by the community, at least not yet. Inspired by Dodgeball, a popular friend-tracking service, Cellphedia suggests something more along the lines of a massive, multi-user trivia game than a serious knowledge resource. It’s the kind of street research that is becoming more common. Answers on impulse. The web overlayed on the physical world.
Category Archives: the_networked_book
BBC rhapsody
Etymology: Latin rhapsodia, from Greek rhapsoidia recitation of selections from epic poetry, rhapsody, from rhapsoidos rhapsodist, from rhaptein to sew, stitch together – Merriam-Webster OnLine
The BBC is moving into web services, allowing the public to build applications that repurpose BBC content.
See also:
“your news, your pictures”
“find it rip it mix it share it”
lost recording of Douglas Adams, and, Flash in the pan
Douglas Adams recorded this (slightly hyperbolic) audio piece back in 1993 to promote the Voyager Expanded Books series. On “getting the book invented”:
 I recently saw the new Hitchhiker’s Guide to the Galaxy movie, which features as one of its central characters a very powerful electronic book – a guide to “life, the universe and everything.” Coming away, I felt a bit uneasy. Could this be the future of the book in the age of Adobe-Macromedia? As portrayed in the film, the Guide is essentially a compendium of Flash animations, with a little bit of text, and a wry British voiceover. Granted, it’s just a narrative device in a film, designed more for style than for content. But is this any less true in real life?.. with all these websites built in Flash, and all the Flash-enhanced garbage on television – especially in ads and sports coverage (notice how TV’s become a lot more like a video game?). The same goes for the film. Though chock-a-block with spiffy visual effects, and flavored with Douglas Adams’ unmistakable wit, it’s basically all style, all pose – visual fireworks for a passive viewer. We have only just started to explore the frontier of media-rich, networked books. But if “FlashAcrobat” becomes the writing tool of choice, that just might end up preempting any serious consideration of an active, critical role for the reader. Books become the half time show at the Super Bowl. Flash frenzy…
I recently saw the new Hitchhiker’s Guide to the Galaxy movie, which features as one of its central characters a very powerful electronic book – a guide to “life, the universe and everything.” Coming away, I felt a bit uneasy. Could this be the future of the book in the age of Adobe-Macromedia? As portrayed in the film, the Guide is essentially a compendium of Flash animations, with a little bit of text, and a wry British voiceover. Granted, it’s just a narrative device in a film, designed more for style than for content. But is this any less true in real life?.. with all these websites built in Flash, and all the Flash-enhanced garbage on television – especially in ads and sports coverage (notice how TV’s become a lot more like a video game?). The same goes for the film. Though chock-a-block with spiffy visual effects, and flavored with Douglas Adams’ unmistakable wit, it’s basically all style, all pose – visual fireworks for a passive viewer. We have only just started to explore the frontier of media-rich, networked books. But if “FlashAcrobat” becomes the writing tool of choice, that just might end up preempting any serious consideration of an active, critical role for the reader. Books become the half time show at the Super Bowl. Flash frenzy…




Paul Boutin, writing last week in Slate, makes draws a more encouraging parallel to the fictional Guide: Wikipedia. “..a real-life Hitchhiker’s Guide: huge, nerdy, and imprecise.” I had not been aware that Adams, before his untimely death in 2001, had experimented with his own web version of the Guide, a sort of proto-Wikipedia called h2g2, hosted by the BBC. Flipping through just a few of the articles, it’s interesting to see a collaborative work sustaining a unified authorial voice. The tone, not to mention the choice of subjects, comes across as unmistakably Adams – the ur-author – even though the guide was built by diverse contributors, in more or less the same fashion as Wikipedia. Here’s the intro paragraph from the article “The Problem with Driving Directions”:
“In the absence of in-car electronic route maps, driving directions are sets of instructions given to drivers in order for them to reach their desired destination. These basically come in two different forms: oral and written. Whether oral or written, they are widely used due to the fact that people often have no idea how to get to where they are going, and naturally assume that they are the only ones that do not know, and so ask someone else. Unfortunately, this other person tends not to know either.”
Building on Boutin’s comparison, you could argue that Wikipedia is simply imitating the tone and format of a paper encyclopedia, much as Adams’ followers in h2g2 are emulating the style of his novels. As a reference tool, Wikipedia may have far outstripped Adams’ project, but questions of accuracy and reliability persist. h2g2, on the other hand, sits much more comfortably in its skin, cheerfully acknowledging that it contains “many omissions,” and “much that is apocryphal, or at least wildly inaccurate.” A much more serious and important endeavor, Wikipedia is still wrestling with the anxiety of influence exerted by its forebear, the encyclopedia. Over time, will its voice change?
is the information any good?…don’t ask Google
Lately, I’ve been thinking about quantitative data vs. qualitative data and noticing that the web is really good at analyzing, packaging, and delivering the former, but woefully barren when it comes to the latter. The really elegant digital visualizations that I’ve seen work with quantitative data. They can show you, for example, the top news stories of the hour, day, or week; the spatial position and relative frequency of words in a novel; the most popular tags, etc… Search engines also privilege quantitative information; the first site that shows up on the Google list is usually the most popular. But determining the quality of that data is left, almost entirely, up to the user. Returning to a point I tried to make in an earlier post, the web is like high school popularity is not always a sign of quality, reliability, or substance.
Let’s take the news for example: the results of a national survey on media consumption conducted by The Pew Research Center and released last year by the Brookings Institute, suggest “that news audiences are increasingly polarized, fragmented, and skeptical, opting for news outlets that most closely resemble their own ideologies…This shared skepticism not only applies to “opposition” news sources, but to the media in general–more than half of those surveyed said they don’t trust the news media…Tom Rosenstiel, director of the Project for Excellent in Journalism. “People want to know, ‘Why should I believe that?'”
Why can’t we use technology to answer this need? What if instead of serving up the most popular stories, we created search engines and visualizations that identified the best stories, ranking information according to quality? Programs that answer the following concerns:
• how well-informed is the writer/news agency?
• are they honest?
• how good is the writing?
• how good is the art/photography/video?
• what are their political motivations?
• who are they paid by/owned by?
Many of these questions require investigation and/or subjective answers. Since subjectivity is still a uniquely human form of processing and evaluating, what I am really calling for is a program that helps us organize the veritable sea of human opinion surging about on the web. The news is not the only area where humans need humans to figure out what they should pay attention to. The massive amount of content that is being generated through the web creates an urgent need for filters in almost every imaginable category. Someone needs to design a critical apparatus for our networked world.
web 3.0 – all consuming
Dan Gillmor has written a nice, accessible overview of the evolution of the web in his periodic column for the Financial Times. As he sketches it, vesion 1.0 was a “fairly static,” “read-only” affair – sites were relatively basic and we checked them for new content or downloads. Online retail and search engines sprang up, essentially to help us find things to read, while things like GeoCities made it possible for anyone to have their own site. With 2.0 it became a two-way street – a “read-write” web, with its poster child the blog. Now, we are learning how to weave all the pieces together and to recombine them in innovative ways – this is version 3.0.
The emerging web is one in which the machines talk as much to each other as humans talk to machines or other humans. As the net is the rough equivalent of a computer operating system, we’re learning how to program the web itself.
A big part of 3.0 are the “web services” that can be built with a site’s “applications programming interface,” or API. An API is essentially a window into a site’s code that programmers can use to build derivative applications. Google, Yahoo, Amazon, and Flickr all have APIs. Gillmor points to a wonderful site – ALL consuming – that uses the Amazon API to build communities around the media – books, music, film – that people are consuming. You simply post the latest entree in your media diet – anything that can be found on Amazon – and then add tags and comments. People inevitably find each other through what they are reading and discussions can ensue. This is an interesting step toward the real-time reading communities that will be possible when we have dynamic electronic books that can plug into the network.
wikipedia keeps apace
Barely 24 hours after being selected as the 265th Pope, Cardinal Joseph Ratzinger, now Benedict XVI, has his own Wikipedia article. Actually, Ratzinger did previously have his own page, but it was moved yesterday to the new Benedict XVI address and has since undergone a massive overhaul.  The revision history, already quite long, captures in miniature the stormy debate that has raged across the world since the news broke. Early on in the history, you see the tireless Wikipedians wrestling over passages dealing with the pontiff’s early years in Germany, where he was a member of the Hitler Youth (membership was compulsory). One finds evidence of a virtual tug-of-war waged over a photograph of Ratzinger as a boy, wearing what appears to be the crisp uniform and official pin of the Hitlerjugend. The photo was eventually scrapped amid doubts about its veracity and copyright status.
The revision history, already quite long, captures in miniature the stormy debate that has raged across the world since the news broke. Early on in the history, you see the tireless Wikipedians wrestling over passages dealing with the pontiff’s early years in Germany, where he was a member of the Hitler Youth (membership was compulsory). One finds evidence of a virtual tug-of-war waged over a photograph of Ratzinger as a boy, wearing what appears to be the crisp uniform and official pin of the Hitlerjugend. The photo was eventually scrapped amid doubts about its veracity and copyright status.
Scanning across the revision history, it’s hard not be to impressed by the vigilance, passion and sheer fussiness that go into the building of a Wikipedia article. Like referees, the writers are constantly throwing down flags for excessive “editorializing” or “POV,” challenging each other on accuracy, grammar, and structure. There are also frequent acts of vandalism to deal with (all the more so, I imagine, with an article like this). Earlier today, for instance, some teenager replaced the Pope’s headshot with a picture of himself. But within a minute, it was changed back. The strength of the Wikipedia is the size of its community – illustrating the “group-forming networks law” that Kim discusses in the previous post, “the web is like high school.”
Not long ago, I posted about a new visualization tool that depicts Wikipedia revision histories over time, showing the shape of an article as it grows and the various users that impact it. For articles on controversial subjects – like popes – it would be fascinating to see these histories depicted as conversations, for that is, in essence, what they are. Any conversation that involves more than two parties cannot be accurately portrayed by a linear stream. There are multiple forks, circles, revolutions, and returns that cannot be captured by a straight line. Often, we are responding to something further up (or down) in the stream, but everything appears sequentially according to the time it was posted. We are still struggling on the web to find a better way to visualize conversations.
It’s also strange to think of an encyclopedia article as news. But that’s definitely what’s happening here, and that’s why Dan Gillmor calls attention to the article on his blog (“How the Community Can Work, Fast”). If newspapers are the “rough draft of history” and encyclopedias are the stable, authoritative version, it seems Wikipedia is somewhere in the middle.
This image sums it up well. It appears at the top of the Benedict XVI page, or above any other article that is similarly au courant.

the web is like high school
Social networking software is breeding a new paradigm in web publishing. The exponential growth potential of group forming networks is shifting the way we assign value to websites. In paper entitled “That Sneaky Exponential–Beyond Metcalfe’s Law to the Power of Community Building” Dr. David P. Reed, a computer scientist, and discoverer of “Reed’s Law,” a scaling law for group-forming architectures, says: “What’s important in a network changes as the network scale shifts. In a network dominated by linear connectivity value growth, “content is king.” That is, in such networks, there is a small number of sources (publishers or makers) of content that every user selects from. The sources compete for users based on the value of their content (published stories, published images, standardized consumer goods). Where Metcalfe’s Law dominates, transactions become central. The stuff that is traded in transactions (be it email or voice mail, money, securities, contracted services, or whatnot) are king. And where the GFN law dominates, the central role is filled by jointly constructed value (such as specialized newsgroups, joint responses to RFPs, gossip, etc.).”
Reed makes a distinction between linear connectivity value growth (where content is king) and GFNs (group forming networks, like the internet) where value (and presumably content) is jointly constructed and grows as the network grows. Wikipedia is a good example, the larger the network of users and contributors the better the content will be (because you draw on a wider knowledge base) and the more valuable the network itself will be (since it has created a large number of potential connections). He also says that the value/cost of services or content grows more slowly than the value of the network. Therefore, content is no longer king in terms of return on investment.
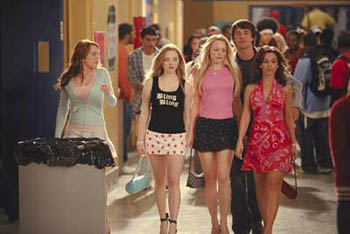
Does this mean that the web is becoming more like high school, a place where relative value is assigned based on how many people like you? And where popularity is not always a sign of spectacular “content.” You don’t need to be smart, hard-working, honest, nice, or interesting to be the high-school “it” girl (or boy). In some cases you don’t even have to be attractive or rich, you just have to be sought-after. In other words, to be popular you have to be popular. That’s it.
SO…if vigorously networked sites are becoming more valuable, are we going to see a substantial shift in web building strategies and goals–from making robust content to making robust cliques? Dr. Reed would probably answer in the affirmative. His recipe for internet success: “whoever forms the biggest, most robust communities will win.”
as u like it – a networked bibliography
This past weekend I attended some of the keynote lectures at the Interactive Multimedia Culture Expo at the Chelsea Art Museum in New York. Among the speakers was Clay Shirky, who gave a quick, energetic talk on “folksonomies” – user-generated taxonomies (i.e. tags) – and how they are changing, from the bottom up, the way we organize information. Folksonomies are still in an infant stage of development, and it remains to be seen how they will develop and refine themselves. Already, it is getting to be a bit confusing and overwhelming. We are in the process of building, collectively, one tag at a time, a massive library. Clearly, we need tools that will help us navigate it.
 Something to watch is how folksonomies are converging with social software platforms like Flickr. What’s interesting is how communities form around specific interests – photos, for instance – and develop shared vocabularies. You also have the bookmarking model pioneered by del.icio.us, which essentially empowers each individual web user as a curator of links. People can link to your page, or subscribe with a feed reader. Eventually, word might spread of particular “editors” with particularly valuable content, organized particularly well. New forms of authority are thereby engendered.
Something to watch is how folksonomies are converging with social software platforms like Flickr. What’s interesting is how communities form around specific interests – photos, for instance – and develop shared vocabularies. You also have the bookmarking model pioneered by del.icio.us, which essentially empowers each individual web user as a curator of links. People can link to your page, or subscribe with a feed reader. Eventually, word might spread of particular “editors” with particularly valuable content, organized particularly well. New forms of authority are thereby engendered.
Shirky mentioned an interesting site that is sort of a cross between these two models. CiteULike takes the tag-based bookmark classification system of del.icio.us and applies it exclusively to papers in academic journals, thereby carving out a defined community of interest, like Flickr.
“CiteULike is a free service to help academics to share, store, and organise the academic papers they are reading. When you see a paper on the web that interests you, you can click one button and have it added to your personal library. CiteULike automatically extracts the citation details, so there’s no need to type them in yourself. It all works from within your web browser. There’s no need to install any special software.”
Essentially, CiteULike is an enormous networked bibliography. On the first page, recently posted papers are listed under the header, “everyone’s library.” To the right is an array of the most popular tags, varying in size according to popularity (like in Flickr). Each tag page has an RSS feed that you can syndicate. You can also form or join groups around a specific subject area. As of this writing, there are articles bookmarked from 6,498 journals, primarily in biology in medicine, “but there is no reason why, say, history or philosophy bibliographies should not be equally prevalent.” So says Richard Cameron, who wrote the site this past November and is its sole operator. Citations are automatically extracted for bookmarked articles, but only if they come from a source that CiteULike supports (list here, scroll down). You can enter metadata manually if you are are not submitting from a vetted source, but your link will appear only on your personal bookmarks page, not on the homepage or in tag searches. This is to maintain a peer review standard for all submitted links, and to guard against “lunatics.” CiteULike says it is looking to steadily expand its pool of supported sources.
CiteULike might eventually fizzle out. Or it might mushroom into something massively popular (it’s already running in five additional languages). Perhaps it will merge with other social software platforms into a more comprehensive folksonomic universe. Perhaps Google will buy it up. It’s impossible to predict. But CiteULike is a valuable experiment in harnessing the power of focused communities, and in creating the tools for navigating our nascent library. It might also solve some of the problems put forth in Kim’s post, “weaving textbooks into the web.” Worth keeping an eye on.
one tree in a forest of information

![]() This tree is made of all the pages, links and data on our site – built with a cool processing applet on texone.org (via reBlog ).
This tree is made of all the pages, links and data on our site – built with a cool processing applet on texone.org (via reBlog ).
“tree accesses the source code of a web domain through it’s url and transforms the syntactic structure of the web site into a tree structure represented by an image. this image illustrates a tree with trunk, branches and ramifications. first each tree is initialized, than all html links are detected, chronologically saved and finally displayed.”
It also builds separate trees for external links, creating entire forests of information. For some reason, our one external tree was a stubby, brown little runt for worldbook.com/info, which I’m pretty sure we do not link to, so I’ve left it off. I’m not sure why it didn’t pick up on our real external links. I’m also not sure exactly how to read the tree, but I guess I can see the basic nature of if:book represented – i.e. a blog is pretty simple structurally but with a lot of content, hence our shaggy, dense foliage on a slender trunk. I also made trees for Google and the New York Times and they were much less woolly and not green like ours.
The texone guys have also recorded the sound of data forests growing. Apparently, every node on a tree – each trunk segment, branch, and leaf – emits a piece of MIDI data – a digital note, varying in pitch according to placement on the tree (high notes are toward the top). They recorded the output for different trees and filtered it through various sound palettes (different types or arrays of instruments). A couple of examples are posted on their site. I’ve put one of them below.
contagious media: symptom of what’s to come?
Here’s a rare peek into the inner workings of the institute: our discussion about viral media that came out of a debate over what to do with the Gates Memory Project. I’ve excerpted from last night’s email conversation….
Ben starts by saying:
Genesis and entropy are both accelerated on the web. Within moments, you can get something out there and have everybody talking about it. But the life can drain out just as quickly. I think it’s fair to say that energy [for the Gates Collective Memory project] is waning, but by refocusing on a single goal, we can perhaps keep this thing afloat…
Bob replies:
absolutely do not want to stop yet; haven’t done enough to have any lasting impact;
Dan says:
Not to derail the conversation by dragging into the realms of the meta, but might the arc that Ben’s describing (an initial flair-up of interest, followed by declining returns) be interesting in & of itself? It seems like the internet is very good at blowing up interesting things at the moment (viz: the contagious media thing Kim forwarded), but it’s (generally) not very good at sustaining interest (or scrutiny). (A major & significant exception: when a community springs up around something.) Occasionally you get a “where are they now?” thread on Boing Boing or Slashdot or something, but that’s very much the exception & not the rule.
This is maybe something that’s important if we’re considering the future of books. The information arc of the printed book seems to be very different: if there’s not a media circus around the launch of the book, there’s a very slow pickup, lasting, conceivably, a very long time. Electronic media seem to be much more time-sensitive.
Bob replies:
EXCELLENT point!
Dan says:
But not a particularly novel one. Certainly someone’s done some thinking about this? I’m not sure where to start looking . . .
Kim says:
Some ideas of where to start looking:
Eyebeam’s Contagious Media Experiments
Exhibition at the New Museum of Contemporary Art / Chelsea
CONTAGIOUS MEDIA
April 28 – June 4, 2005
Media Lounge
Review/preview of show
Dan replies:
This is kinda the opposite of what I’m interested in here. I think it’s great that the Internet spreads things virally, but these things burn out very quickly: the Peretti’s projects seemed “yesterday” a couple years ago. Nobody checks into blackpeopleloveus.com regularly – people visited once & got the joke (or didn’t). Do we really need a loving history of “all your base are belong to us”? It was funny – and certainly signifies a moment of our collective interaction with the Internet very precisely – but a museum exhibitions seems almost beside the point. You don’t put a pop song into a museum – and I say that with a full appreciation of pop songs.
To carry the pop song analogy further: in a pop-song world, can you have Bach? if you wanted to have Bach?
(I don’t think The Gates really fit into this sort of framework, because there were personal interactions with them. Ben – for example – can tell stories about the gates in a way that we can’t really tell (interesting) stories about the dancing baby.)
Kim replies:
Social critiques like www.whatisvictoriassecret.com which posed women in sexy underware barfing over the toilet really did say something about body image and the way the advertising industry manipulates women. And the Nike sweatshop emails forced Nike to address labor issues. These websites are not built to last in the same way oil paintings and poems are, but I do think they are a significant cultural commentary and a new form of activism. In this sense I suppose, the Gates do not fit, because they have no political goals.
We should also consider contagious media that parodies an over-hyped current event, a good example is this blog written by Brittany Spears’ fetus Don’t forget, the most popular website about the Gates was a parody (the Sommerville Gates). it followed this formula, went viral and got tens of thousands of hits.
I think the contagious media element is important for our project. The Gates themselves were temporary and the material we are gathering is, ostensibly, finite (i.e. Nobody is going to go out and take a picture of the Gates tomorrow). Therefore, we need to draw attention to the project now. I don’t think personal interactions or the potential for stories/complexity prevents us from making at least some part of this project contagious.
I don’t get the pop-song analogy. We do have museums for pop-music. Jazz, Motown, Elvis, the Beatles, they are not trivial and we still have Bach.
Ben says:
I agree it would be interesting to look at the project in terms of its arc – a web arc versus a print arc. It might be interesting also to consider this in terms of closed and exposed. Writing a book is a relatively solitary and contained act (unless it’s built on interviews and field research). But still, a work in progress is usually kept very private and tucked away. Only upon being published does it open up to the world. Our project, however, started with a large number of people and a fair bit of attention, but then gradually contracted to an inner core. Now we try to make sense of that dizzying encounter with the larger world. You could say that print books embody thinking before speaking, whereas the web fosters speaking first and thinking later, or not at all.
As for Bach, I think he’s pretty much impossible in a pop world, except as reduced to a pop song – the played-to-death cello suite accompanying a Lexus gliding across your TV. Someone today with Bach’s genius probably couldn’t impact the development of music in nearly as big a way. Maybe he would just become a scientist. And it’s true, we don’t really put pop songs in museums. Only one of the things Kim mentions is a place, and that’s a museum to a legendary person, not a song. I suppose there’s the rock and roll hall of fame, but that strikes me as going to the taxidermist’s and calling it a zoo. I guess what I’m trying to say is that there’s a similar entombed quality to this Contagious Media Showdown Eyebeam is hosting. It’s proof that the “all your base,” “blackpeopleloveus” variety of web contagion is passé. Drag racing diseases isn’t subversive, it’s just referential. But I agree with Kim that there continue to be interesting and sometimes powerful instances of contagious media. But a big part of their power is that they come out of nowhere. The minute you announce that something is contagious, you kind of kill its coolness. I wonder if anything worthwhile will come out of that contest.
It’s interesting to analyze all this in terms of trying to make something coherent and lasting on the web. But I’m not sure we need to lob a contagious grenade of our own. What sort of thing are you imagining?
–end of email exchange, conversation continues in the comment field–