
(Jeff Drouin is in the English Ph.D. Program at The Graduate Center of the City University of New York)
About three weeks ago I had lunch with Ben, Eddie, Dan, and Jesse to talk about starting a community with one of my projects, the Ecclesiastical Proust Archive. I heard of the Institute for the Future of the Book some time ago in a seminar meeting (I think) and began reading the blog regularly last Summer, when I noticed the archive was mentioned in a comment on Sarah Northmore’s post regarding Hurricane Katrina and print publishing infrastructure. The Institute is on the forefront of textual theory and criticism (among many other things), and if:book is a great model for the kind of discourse I want to happen at the Proust archive. When I finally started thinking about how to make my project collaborative I decided to contact the Institute, since we’re all in Brooklyn, to see if we could meet. I had an absolute blast and left their place swimming in ideas!
 While my main interest was in starting a community, I had other ideas — about making the archive more editable by readers — that I thought would form a separate discussion. But once we started talking I was surprised by how intimately the two were bound together.
While my main interest was in starting a community, I had other ideas — about making the archive more editable by readers — that I thought would form a separate discussion. But once we started talking I was surprised by how intimately the two were bound together.
For those who might not know, The Ecclesiastical Proust Archive is an online tool for the analysis and discussion of à la recherche du temps perdu (In Search of Lost Time). It’s a searchable database pairing all 336 church-related passages in the (translated) novel with images depicting the original churches or related scenes. The search results also provide paratextual information about the pagination (it’s tied to a specific print edition), the story context (since the passages are violently decontextualized), and a set of associations (concepts, themes, important details, like tags in a blog) for each passage. My purpose in making it was to perform a meditation on the church motif in the Recherche as well as a study on the nature of narrative.
I think the archive could be a fertile space for collaborative discourse on Proust, narratology, technology, the future of the humanities, and other topics related to its mission. A brief example of that kind of discussion can be seen in this forum exchange on the classification of associations. Also, the church motif — which some might think too narrow — actually forms the central metaphor for the construction of the Recherche itself and has an almost universal valence within it. (More on that topic in this recent post on the archive blog).
Following the if:book model, the archive could also be a spawning pool for other scholars’ projects, where they can present and hone ideas in a concentrated, collaborative environment. Sort of like what the Institute did with Mitchell Stephens’ Without Gods and Holy of Holies, a move away from the ‘lone scholar in the archive’ model that still persists in academic humanities today.
One of the recurring points in our conversation at the Institute was that the Ecclesiastical Proust Archive, as currently constructed around the church motif, is “my reading” of Proust. It might be difficult to get others on board if their readings — on gender, phenomenology, synaesthesia, or whatever else — would have little impact on the archive itself (as opposed to the discussion spaces). This complex topic and its practical ramifications were treated more fully in this recent post on the archive blog.
I’m really struck by the notion of a “reading” as not just a private experience or a public writing about a text, but also the building of a dynamic thing. This is certainly an advantage offered by social software and networked media, and I think the humanities should be exploring this kind of research practice in earnest. Most digital archives in my field provide material but go no further. That’s a good thing, of course, because many of them are immensely useful and important, such as the Kolb-Proust Archive for Research at the University of Illinois, Urbana-Champaign. Some archives — such as the NINES project — also allow readers to upload and tag content (subject to peer review). The Ecclesiastical Proust Archive differs from these in that it applies the archival model to perform criticism on a particular literary text, to document a single category of lexia for the experience and articulation of textuality.
 If the Ecclesiastical Proust Archive widens to enable readers to add passages according to their own readings (let’s pretend for the moment that copyright infringement doesn’t exist), to tag passages, add images, add video or music, and so on, it would eventually become a sprawling, unwieldy, and probably unbalanced mess. That is the very nature of an Archive. Fine. But then the original purpose of the project — doing focused literary criticism and a study of narrative — might be lost.
If the Ecclesiastical Proust Archive widens to enable readers to add passages according to their own readings (let’s pretend for the moment that copyright infringement doesn’t exist), to tag passages, add images, add video or music, and so on, it would eventually become a sprawling, unwieldy, and probably unbalanced mess. That is the very nature of an Archive. Fine. But then the original purpose of the project — doing focused literary criticism and a study of narrative — might be lost.
If the archive continues to be built along the church motif, there might be enough work to interest collaborators. The enhancements I currently envision include a French version of the search engine, the translation of some of the site into French, rewriting the search engine in PHP/MySQL, creating a folksonomic functionality for passages and images, and creating commentary space within the search results (and making that searchable). That’s some heavy work, and a grant would probably go a long way toward attracting collaborators.
So my sense is that the Proust archive could become one of two things, or two separate things. It could continue along its current ecclesiastical path as a focused and led project with more-or-less particular roles, which might be sufficient to allow collaborators a sense of ownership. Or it could become more encyclopedic (dare I say catholic?) like a wiki. Either way, the organizational and logistical practices would need to be carefully planned. Both ways offer different levels of open-endedness. And both ways dovetail with the very interesting discussion that has been happening around Ben’s recent post on the million penguins collaborative wiki-novel.
Right now I’m trying to get feedback on the archive in order to develop the best plan possible. I’ll be demonstrating it and raising similar questions at the Society for Textual Scholarship conference at NYU in mid-March. So please feel free to mention the archive to anyone who might be interested and encourage them to contact me at jdrouin@gc.cuny.edu. And please feel free to offer thoughts, comments, questions, criticism, etc. The discussion forum and blog are there to document the archive’s development as well.
Thanks for reading this very long post. It’s difficult to do anything small-scale with Proust!
Category Archives: tagging
google flirts with image tagging
 Ars Technica reports that Google has begun outsourcing, or “crowdsourcing,” the task of tagging its image database by asking people to play a simple picture labeling game. The game pairs you with a randomly selected online partner, then, for 90 seconds, runs you through a sequence of thumbnail images, asking you to add as many labels as come to mind. Images advance whenever you and your partner hit upon a match (an agreed-upon tag), or when you agree to take a pass.
Ars Technica reports that Google has begun outsourcing, or “crowdsourcing,” the task of tagging its image database by asking people to play a simple picture labeling game. The game pairs you with a randomly selected online partner, then, for 90 seconds, runs you through a sequence of thumbnail images, asking you to add as many labels as come to mind. Images advance whenever you and your partner hit upon a match (an agreed-upon tag), or when you agree to take a pass.
I played a few rounds but quickly grew tired of the bland consensus that the game encourages. Matches tend to be banal, basic descriptors, while anything tricky usually results in a pass. In other words, all the pleasure of folksonomies — splicing one’s own idiosyncratic sense of things with the usually staid task of classification — is removed here. I don’t see why they don’t open the database up to much broader tagging. Integrate it with the image search and harvest a bigger crop of metadata.
Right now, it’s more like Tom Sawyer tricking the other boys into whitewashing the fence. Only, I don’t think many will fall for this one because there’s no real incentive to participation beyond a halfhearted points system. For every matched tag, you and your partner score points, which accumulate in your Google account the more you play. As far as I can tell, though, points don’t actually earn you anything apart from a shot at ranking in the top five labelers, which Google lists at the end of each game. Whitewash, anyone?
In some ways, this reminded me of Amazon’s Mechanical Turk, an “artificial artificial intelligence” service where anyone can take a stab at various HIT’s (human intelligence tasks) that other users have posted. Tasks include anything from checking business hours on restaurant web sites against info in an online directory, to transcribing podcasts (there are a lot of these). “Typically these tasks are extraordinarily difficult for computers, but simple for humans to answer,” the site explains. In contrast to the Google image game, with the Mechanical Turk, you can actually get paid. Fees per HIT range from a single penny to several dollars.
I’m curious to see whether Google goes further with tagging. Flickr has fostered the creation of a sprawling user-generated taxonomy for its millions of images, but the incentives to tagging there are strong and inextricably tied to users’ personal investment in the production and sharing of images, and the building of community. Amazon, for its part, throws money into the mix, which (however modest the sums at stake) makes Mechanical Turk an intriguing, and possibly entertaining, business experiment, not to mention a place to make a few extra bucks. Google’s experiment offers neither, so it’s not clear to me why people should invest.
flickr as virtual museum

A local story. The Brooklyn Museum has been availing itself of various services at Flickr in conjunction with its new “Grafitti” exhibit, assembling photo sets and creating a group photo pool. In addition, the museum welcomes anyone to contribute photographs of grafitti from around Brooklyn to be incorporated into the main photo stream, along with images of a growing public grafitti mural on-site at the museum where visitors can pick up a colored pencil and start scribbling away. Here’s a picture from the first week of the mural:

This is an interesting case of a major cultural institution nurturing an outer curatorial ring to complement, and even inform, a central exhibit (the Institute conducted a similar experiment around Christo’s Gates installation in Central Park, 2005). It’s especially well suited to a show about grafitti, which is already a popular subject of amateur street photography. The museum has cleverly enlisted the collective eyes of the community to cover a terrain (a good chunk of the total surface area of Brooklyn) far too vast for any single organization to fully survey. (The quip has no doubt already been made that users be sure not forget to tag their photos.)
Thanks, Alex, for pointing this out.
academic library explores tagging

The ever-innovative University of Pennsylvania library is piloting a new social bookmarking system (like del.icio.us or CiteULike), in which the Penn community can tag resources and catalog items within its library system, as well as general sites from around the web. There’s also the option of grouping links thematically into “projects,” which reminds me of Amazon’s “listmania,” where readers compile public book lists on specific topics to guide other customers. It’s very exciting to see a library experimenting with folksonomies: exploring how top-down classification systems can productively collide with grassroots organization.
smarter links for a better wikipedia
As Wikipedia continues its evolution, smaller and smaller pieces of its infrastructure come up for improvement. The latest piece to step forward to undergo enhancement: the link. “Computer scientists at the University of Karlsruhe in Germany have developed modifications to Wikipedia’s underlying software that would let editors add extra meaning to the links between pages of the encyclopaedia.” (full article) While this particular idea isn’t totally new (at least one previous attempt has been made: platypuswiki), SemanticWiki is using a high profile digital celebrity, which brings media attention and momentum.
What’s happening here is that under the Wikipedia skin, the SemanticWiki uses an extra bit of syntax in the link markup to inject machine readable information. A normal link in wikipedia is coded like this [link to a wiki page] or [http://www.someothersite.com link to an outside page]. What more do you need? Well, if by “you” I mean humans, the answer is: not much. We can gather context from the surrounding text. But our computers get left out in the cold. They aren’t smart enough to understand the context of a link well enough to make semantic decisions with the form “this link is related to this page this way”. Even among search engine algorithms, where PageRank rules them all, PageRank counts all links as votes, which increase the linked page’s value. Even PageRank isn’t bright enough to understand that you might link to something to refute or denigrate its value. When we write, we rely on judgement by human readers to make sense of a link’s context and purpose. The researchers at Karlsruhe, on the other hand, are enabling machine comprehension by inserting that contextual meaning directly into the links.
SemanticWiki links look just like Wikipedia links, only slightly longer. They include info like
- categories: An article on Karlsruhe, a city in Germany, could be placed in the City Category by adding
[[Category: City]]to the page. - More significantly, you can add typed relationships.
Karlsruhe [[:is located in::Germany]]would show up as Karlsruhe is located in Germany (the : before is located in saves typing). Other examples: in the Washington D.C. article, you can add [[is capital of:: United States of America]]. The types of relationships (“is capital of”) can proliferate endlessly. - attributes, which specify simple properties related to the content of an article without creating a link to a new article. For example,
[[population:=3,396,990]]
Adding semantic information to links is a good idea, and hewing closely to the current Wikipedia syntax is a smart tactic. But here’s why I’m not more optimistic: this solution combines the messiness of tagging with the bother of writing machine readable syntax. This combo reminds me of a great Simpsons quote, where Homer says, “Nuts and gum, together at last!” Tagging and semantic are not complementary functions – tagging was invented to put humans first, to relieve our fuzzy brains from the mechanical strictures of machine readable categorization; writing relationships in a machine readable format puts the machine squarely in front. It requires the proliferation of wikipedia type articles to explain each of the typed relationships and property names, which can quickly become unmaintainable by humans, exacerbating the very problem it’s trying to solve.
But perhaps I am underestimating the power of the network. Maybe the dedication of the Wikipedia community can overcome those intractible systemic problems. Through the quiet work of the gardeners who sleeplessly tend their alphanumeric plots, the fact-checkers and passers-by, maybe the SemanticWiki will sprout links with both human and computer sensible meanings. It’s feasible that the size of the network will self-generate consensus on the typology and terminology for links. And it’s likely that if Wikipedia does it, it won’t be long before semantic linking makes its way into the rest of the web in some fashion. If this is a success, I can foresee the semantic web becoming a reality, finally bursting forth from the SemanticWiki seed.
UPDATE:
I left off the part about how humans benefit from SemanticWiki type links. Obviously this better be good for something other than bringing our computers up to a second grade reading level. It should enable computers to do what they do best: sort through massive piles of information in milliseconds.
How can I search, using semantic annotations? – It is possible to search for the entered information in two differnt ways. On the one hand, one can enter inline queries in articles. The results of these queries are then inserted into the article instead of the query. On the other hand, one can use a basic search form, which also allows you to do some nice things, such as picture search and basic wildcard search.
For example, if I wanted to write an article on Acting in Boston, I might want a list of all the actors who were born in Boston. How would I do this now? I would count on the network to maintain a list of Bostonian thespians. But with SemanticWiki I can just add this: <ask>[[Category:Actor]] [[born in::Boston]], which will replace the inline query with the desired list of actors.
To do a more straightforward search I would go to the basic search page. If I had any questions about Berlin, I would enter it into the Subject field. SemanticWiki would return a list of short sentences where Berlin is the subject.
But this semantic functionality is limited to simple constructions and nouns—it is not well suited for concepts like 'politics,' or 'vacation'. One other point: SemanticWiki relationships are bounded by the size of the wiki. Yes, digital encyclopedias will eventually cover a wide range of human knowledge, but never all. In the end, SemanticWiki promises a digital network populated by better links, but it will take the cooperation of the vast human network to build it up.
presidents’ day
Few would disagree that Presidents’ Day, though in theory a celebration of the nation’s highest office, is actually one of our blandest holidays — not so much about history as the resuscitation of commerce from the post-holiday slump. Yesterday, however, brought a refreshing change.

Spending the afternoon at the institute was Holly Shulman, a historian from the University of Virginia well known among digital scholarship circles as the force behind the Dolley Madison Project — a comprehensive online portal to the life, letters and times of one of the great figures of the early American republic. So, for once we actually talked about presidential history on Presidents’ Day — only, in this case from the fascinating and chronically under-studied spousal perspective.
Shulman came to discuss possible collaboration on a web-based history project that would piece together the world of America’s founding period — specifically, as experienced and influenced by its leading women. The question, in terms of form, was how to break out of the mould of traditional web archives, which tend to be static and exceedingly hierarchical, and tap more fully into the energies of the network? We’re talking about something you might call open source scholarship — new collaborative methods that take cues from popular social software experiments like Wikipedia, Flickr and del.icio.us yet add new layers and structures that would better ensure high standards of scholarship. In other words: the best of both worlds.
Shulman lamented that the current generation of historians are highly resistant to the idea of electronic publication as anything more than supplemental to print. Even harder to swallow is the open ethos of Wikipedia, commonly regarded as a threat to the hierarchical authority and medieval insularity of academia.
Again, we’re reminded of how fatally behind the times the academy is in terms of communication — both communication among scholars and with the larger world. Shulman’s eyes lit up as we described the recent surge on the web of social software and bottom-up organizational systems like tagging that could potentially create new and unexpected avenues into history.
A small example that recurred in our discussion: Dolley Madison wrote eloquently on grief, mourning and widowhood, yet few would know to seek out her perspective on these matters. Think of how something like tagging, still in an infant stage of development, could begin to solve such a problem, helping scholars, students and general readers unlock the multiple facets of complex historical figures like Madison, and deepening our collective knowledge of subjects — like death and war — that have historically been dominated by men’s accounts. It’s a small example, but points toward something grand.
online retail influencing libraries
The NY Times reports on new web-based services at university libraries that are incorporating features such as personalized recommendations, browsing histories, and email alerts, the sort of thing developed by online retailers like Amazon and Netflix to recreate some of the experience of browsing a physical store. Remember Ranganathan’s fourth law of library science: “save the time of the reader.” The reader and the customer are perhaps becoming one in the same.
It would be interesting if a social software system were emerging for libraries that allowed students and researchers to work alongside librarians in organizing the stacks. Automated recommendations are just the beginning. I’m talking more about value added by the readers themselves (Amazon has does this with reader reviews, Listmania, and So You’d Like To…). A social card catalogue with a tagging system and other reader-supplied metadata where readers could leave comments and bread crumb trails between books. Each card catalogue entry with its own blog and wiki to create a context for the book. Books are not just surrounded by other volumes on the shelves, they are surrounded by people, other points of view, affinities — the kinds of thing that up to this point were too vaporous to collect. This goes back to David Weinberger’s comment on metadata and Google Book Search.
the book in the network – masses of metadata
In this weekend’s Boston Globe, David Weinberger delivers the metadata angle on Google Print:
…despite the present focus on who owns the digitized content of books, the more critical battle for readers will be over how we manage the information about that content-information that’s known technically as metadata.
…we’re going to need massive collections of metadata about each book. Some of this metadata will come from the publishers. But much of it will come from users who write reviews, add comments and annotations to the digital text, and draw connections between, for example, chapters in two different books.
As the digital revolution continues, and as we generate more and more ways of organizing and linking books-integrating information from publishers, libraries and, most radically, other readers-all this metadata will not only let us find books, it will provide the context within which we read them.
The book in the network is a barnacled spirit, carrying with it the sum of its various accretions. Each book is also its own library by virtue not only of what it links to itself, but of what its readers are linking to, of what its readers are reading. Each book is also a milk crate of earlier drafts. It carries its versions with it. A lot of weight for something physically weightless.
the big picture
Though a substantial portion of our reading now takes place online, we still chafe against the electronic page, in part because today’s screens are hostile to the eye, but also, I think, because we are waiting for something new – something beyond a shallow mimicry of print. Occasionally, however, you come across something that suggests a new possibility for what a page, or series of pages, can be when words move to the screen.
I came across such a thing today on CNET’s new site, which has a feature called “The Big Picture,” a dynamic graphical display that places articles at the center of a constellation, drawing connections to related pieces, themes, and company profiles.

Click on another document in the cluster and the items re-arrange around a new center, and so on – ontologies are traced. But CNET’s feature does not go terribly far in illuminating the connections, or rather the different kinds of connections, between articles and ideas. They should consider degrees of relevance, proximity in time, or overlaps in classification. Combined with a tagging system, this could get interesting. As it stands, it doesn’t do much that a simple bullet list of related articles can’t already do admirably, albeit with fewer bells and whistles.
But this is pushing in an interesting direction, testing ways in which a web publication can organize and weave together content, shedding certain holdovers from print that are no longer useful in digital space. CNET should keep playing with this idea of an article ontology viewer – it could be refined into a legitimately useful tool.
human versus algorithm
I just came across Common Times, a new community-generated news aggregation page, part of something called the Common Media Network, that takes the social bookmarking concept of del.icio.us and applies it specifically to news gathering. Anyone can add a story from any source to a series of sections (which seem pre-set and non-editable) arranged on a newspaper-style “front page.” You add links through a bookmarklet on the links bar on your browser. Whenever you come across an article you’d like to submit, you just click the button and a page comes up where you can enter the metadata like tags and comments. Each user has a “channel” – basically a stripped-down blog – where all their links are displayed chronologically with an RSS feed, giving individuals a venue to show their chops as news curators and annotators. You can set it up so links are posted simultaneously to a del.icio.us account (there’s also a Firefox extension that allows you to post stories directly from Bloglines).
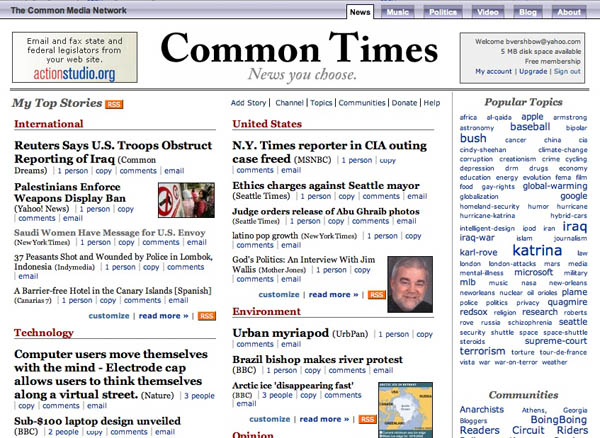
Human aggregation is often more interesting than what the Google News algorithm can turn up, but it can easily mould to the biases of the community. Of course, search algorithms are developed by people, and source lists don’t just manufacture themselves (Google is notoriously tight-lipped about its list of news sources). In the case of something like Common Times, a slick new web application hyped on Boing Boing and other digital culture sites, the communities can be rather self-selecting. Still, this is a very interesting experiment in multi-player annotation. When I first arrived at the front page, not yet knowing how it all worked, I was impressed by the fairly broad spread of stories. And the tag cloud to the right is an interesting little snapshot of the zeitgeist.
(via Infocult)