
On Wednesday, we had the pleasure of spending an afternoon with a group of 22 students from Carleton College who are spending a trimester studying and making digital media under the guidance of John Schott, a professor in the Dept. of Cinema & Media Studies specializing in “personal media” production and network culture. This year, his class is embarking on an off-campus study, a ten-week odyssey beginning in Northfield, Minnesota and taking them to New York, London, Amsterdam and Berlin. At each stop, they’ll be visiting with new media producers, attending festivals and exhibitions, and documenting their travels in a variety of forms. Needless to say, we’re deeply envious.
The Institute was the first stop on their trip, so we tried to start things off with a flourish. After a brief peak at the office, we brought the class over to Monkeytown, a local cafe and video club with a fantastic cube-shaped salon in the back where gigantic projection screens hang on each of the four walls.

Hooking our computers up to the projectors, we took the students on a tour of what we do: showed them our projects, talked about networked books (it was surreal to see GAM3R 7H30RY blown up 20 feet wide, wavering slightly in the central AC), and finished with a demo of Sophie. John Schott wrote a nice report about our meeting on the class’s blog. Also, for a good introduction to John’s views on personal media production and media literacy, take a look at this interview he gave on a Minnesota video blog back in March.
This is a great group of students he’s assembled, with interests ranging from film production to philosophy to sociology. They also seem to like Macs. This could be an ad for the new MacBook:

We’ve invited them back toward the end of their three weeks in New York to load Sophie onto their laptops before they head off to Europe.
(photos by John Schott)
Category Archives: Sophie
speed dating sophie
Last Tuesday I was formally introduced to Sophie. Our first date left me dazed and confused. She is a powerful multimedia application from New York, well funded and growing under healthy cosmopolitan influences, while I am a digitally challenged graduate student with a dreadful Third World education.  Despite the obvious mismatch, Sophie was surprisingly responsive. For a program that is still a month away from even entering beta purgatory, to freeze up once in a while is perfectly normal. My reaction, on the other hand, was childish and immature. I protested out loud, argued with developers, worried about details, and became permanently infatuated. Now I can’t stop thinking about Sophie.
Despite the obvious mismatch, Sophie was surprisingly responsive. For a program that is still a month away from even entering beta purgatory, to freeze up once in a while is perfectly normal. My reaction, on the other hand, was childish and immature. I protested out loud, argued with developers, worried about details, and became permanently infatuated. Now I can’t stop thinking about Sophie.
The problem is that she lies at the core of everything I want to do. During the next couple of decades I would like to participate in the collaborative development of multimedia ecosystems. Ok, that sounds awfully pretentious. What I really want is to work and play with a bunch of friends in a huge toy factory. My favorite toys are multimedia creatures.
For a while (and halfway-tongue-in-cheek) I have been training myself to think about all kinds of cultural artifacts in evolutionary terms. When I play around with a good old printed book, for example, I try to think about it as a potentially feature-rich creature that, so far as I am concerned, is working very well in frozen text mode. All other noisier and flashier possible forms of behavior have been muted, so to speak, in order to maximize the cultural value of the reading experience.
I think Sophie fascinates me precisely because her future depends so much on achieving a creative balance between simplicity and complexity. If everything goes well, Sophie will be able to handle very intricate tasks in rather plain terms. The program already has an unobtrusive but intuitive interface that would allow first time users to assemble rich multimedia documents in a matter of minutes. A highly sophisticated Sophie document can be embedded as a whole into another Sophie document. Placing an entire library of interconnected multimedia artifacts in a corner of a page within a Sophie “book” would only take a few mouse clicks.
An open source multimedia assembling program is always welcome. Sophie will be particularly good at doing difficult things the easy way, and that is a bonus in an industry cluttered with “advanced” applications that seem to be going in the opposite direction. Given the proper planetary alignment, a nurturing community could grow around the development of extensions and additions to the program. Eventually, Sophie would be unrecognizable, and that is the best thing that can happen to an evolving living thing.
Did I mention that the application has also been conceived as a platform independent application for collaborative multimedia assembling? That’s right; Sophie would eventually allow people to join efforts in authoring and managing complex documents over a network. These are my kind of toys: evolving multimedia artifacts, born on a network, raised by a virtual village, and assembled with a tool that is being develop along similar principles. Very cool stuff.
Strategically speaking, however, the development of Sophie, and the model of collaborative multimedia creation in general, could be better implemented using the notion of software as a service. Downloading an application that would reside in the desktop and then using it to handle files over a network is relatively cumbersome. This model requires periodic updating of the program and a high volume of general traffic up and down the servers.
Under the current paradigm, Sophie is being developed just like Microsoft Word but I would rather work on something more along the lines of Writely. An Ajax-based version of Sophie within a regular web browser like Firefox would maximize the networking capabilities of the application. Full assembly functionality could be hard to achieve this way, but in a tradeoff between fancy multimedia features and wider potential for collaboration I would tend to favor the latter. The evolutionary success of a networked book will depend on the qualities of the network rather than the features of the book.
Online collaboration can be achieved more efficiently by sideloading rather than constantly uploading and downloading files. In an ideal world we would only need to upload original raw files, and only once. Everything else would happen at the server level. Every user would have access to every file and any combination of files at every step during the assembling process, from any computer connected to the internet.
This late in its development, altering the nature of an application like Sophie at this radical level is too difficult. Perhaps the best way to go about it is to release a beta version of the program, in order to broaden its community of developers, and hope that a team of Ajax-savvy people decides to create a browser-based alternative interface for Sophie. In the meantime she should consider setting up a series of dates with the guys at Ajax13. I promise I won’t be jealous.
sophie is well
Yesterday’s post about MediaCommons has generated a number of questions about the whereabouts of “Sophie,” the new environment for digital writing and reading that the institute is working on. I’m delighted to report we are holding an introductory session in LA on august 14/15 for a group of professors that will be using Sophie on several campuses this fall. we’ll be putting up a website, specifically for Sophie in time for a soft public launch in September for anyone who wants to download and use it.
on collaborating with the reader
I’ve been thinking a lot about the idea of reader collaboration, prior to GAM3R TH3ORY‘s publication but to a good deal in response to its impending arrival. This notion clearly means that after the author has done one thing, the “book” becomes the accumulation of author’s and readers’ contributions.
So I’ve been thinking about collaboration. My starting point was something mentioned on my visit to the Institute — that the book’s source needs to be distributed, and it can be altered by the reader. (This is a very big idea, btw, and it’s radically altered my notion of what an e-book format’s obligations are. But that’s another discussion.)
SInce Sophie is an authoring tool, I thought, Why don’t I author something and really see what it can do? So I’ve been working with my own notion of what a book would be like that isn’t wholly limited by its medium being print. And I thought maybe I should let Sophie’s developers in on my ambition so that there’s a possibility that the features I’m envisioning might be included in the program, at least at some point in the future.
I think it’s easiest to understand my notion of collaborating with the reader by describing my work-in-progress.
So the basic notion is fairly simple, realizable already in Flash, say, or SVG:
Imagine a story, with multiple tracks. (I’m actually envisioning a short book, so let’s say 16 or 24 pages and 5 tracks.) On any page, you can go to the next or previous page. Or you can change tracks and see the next or previous page from some other track. It seems just like a 24-page book, except that the 5 tracks provide variations on what is on each page.
That’s not too exotic. And I don’t stray too far from this notion.
The first thing I’d like to do is provide multiple series of illustrations for each track. So track A might display what i call the French illustrations, or the English, or the Klee, and so on. Thus the first capability I would want to see in my authoring/reading tool is a way to change which illustration (or series of illustrations) displays within each track. You still go backwards and forwards, but maybe I like Van Gogh’s illustrations and you like Ansel Adams’. Perhaps I should mention at this point that it’s a children’s book, so I’m not casually speaking about illustrations. They are the central aspect.
The next thing I’d like to do is to allow the reader to supply illustrations, for any page (in any track), and supplant the author’s (or publisher’s) illustrations. So that perhaps my book comes with 4 series of illustrations for each track, but a reader could add many others. If these series were shared (upload your own, download others’), then perhaps you have 9 series for track A and I have 23. There has to be an easy way for the plugging in pieces, which is more on the level I’m expecting a reader to manage, as opposed to the full set of tools the author will access.
With this, the collaboration with the reader becomes two-fold — first the creation can be shared: make your own illustrations. Then, second, each individual instance becomes distinctive. If we trade “copies,” then we see the distinctive choices we each have made. Each instance is unique, especially as it contains series of illustrations that are not shared/distributed at all. In a way this reminds me of the trading card games that my ten-year-old and his friends play. They all purchase the same cards, each possessing hundreds of cards, and collect them into unique decks that they each admire and study (and then compete against, the duel being paramount). Moreover, each has some cards that none of the others has.
In addition to accepting individual illustrations or whole series of illustrations, the book should allow its text to be edited and alternate versions selected for display. I’m not sure whether one text track would be read-only, or if clicking some button would restore the text to its default form in some track, but I’d expect the author’s initial, unedited version should be retrievable in some way.
I’m far less concerned about the text than I am about this capability with illustrations, btw.
Since my project book is intended for children, I’ve thought a lot about the nature of collaboration with them. In this instance, I think will use little or no animation — it’s not an equal collaboration if the initiating author can do tricks to gain attention that the collaborating reader cannot manage. And that is one thing that makes this a book and not an animation or a cartoon and yet still strives to keep its electronicity high.
And my effort at collaboration is more like a teacher’s — here, you write/draw something, and we’ll replace what I’ve done. Perhaps in the end all the words and pictures are yours. My role was to get you started and to provide the framework. But every new collaborator can begin with the pristine master copy that anyone can access (or maybe they’ll start with a local, already altered variant that the teacher gives them). It hasn’t escaped my notice that in fact the collaboration might be between author and a class of students, not just one reader.
So. Likely as not, this first version of Sophie won’tt contain this addition/substitution capability, or perhaps not to the extent I describe. But I hope it can be added to the future feature set, or hooks anyway that will enable some plug-in to provide this capability. Because this type of collaboration seems to me to be essential.
* * *
It seems a natural expectation that a book constructed of multiple units might have multiple paths through it.
In the case of this children’s book, I don’t expect that going from track-A-page-1 to D3 to B4, and so on, is going to provide anything useful.
But I can clearly envision publications — a guidebook, a cookbook, a college course schedule, an anthology of poetry, a collection of photographs, the Meditations of Marcus Aurelius, the Sayings of the Desert Fathers — in which a reader (or a teacher) may beneficially provide paths that an author overlooks. (Each of these examples of course is an instance of wholly independent units.)
In fact, I expect that Sophie’s envisioneers have thought of such circumstances already, but I raise it here as a collateral issue — collaboration with the reader must inevitably involve everything an author touches: the text, the development of the ideas, the sequence in which they are conveyed, how they are illustrated, the conclusions drawn. In a true collaboration, the author becomes something more like a director, operating perhaps at a remove (how active will the author be in reshaping the book after its publication?). Or maybe the director analogy is too strong; perhaps it’s more like an organizer — the Merry Pranksters, Christo, Lev Waleska — who launches his/her book like a vehicle (like Voyager) and then simply rides its momentum.
Once we make the book more collaborative, we remake what it means to author a book, and the creation of a book itself may come to be something more like a play or a movie or a dance, with multiple, recognized contributors.
I’m wondering how far Sophie goes in anticipating these ideas.
a chink in the armor of open source?
With the coming release of Sophie and our recent attendence at the Access 2 Knowledge conference, I find myself thinking about open source software development. The operating system Linux is often used as the shining example of the open source software movement. Slashdot reported an interesting ZDNet UK article, which quoted the head maintainer of the Linux production kernal, Andrew Morton, saying that he is concerned about the large number of long standing bugs in the 2.6 kernal. Software always has bugs being worked out, even the long standing ones that Morton describes. Therefore, the statement is not all that shocking or surprising.
What intrigued me was this following statement:
“One problem is that few developers are motivated to work on bugs, according to Morton. This is particularly a problem for bugs that affect old computers or peripherals, as kernel developers working for corporations don’t tend to care about out-of-date hardware, he said. Nowadays, many kernel developers are employed by IT companies, such as hardware manufacturers, which can cause problems as they can mainly be motivated by self-interest.
“If you’re a company that employs a kernel maintainer, you don’t have an interest in working on a five-year-old peripheral that no one is selling any more. I can understand that, but it is a problem as people are still using that hardware. The presence of that bug affects the whole kernel process, and can hold up the kernel — as there are bugs, but no one is fixing them,” said Morton.
Keeping contributors motivated is crucial to open source endeavors. Reputation is a major factor in what drives people to submit code to the Linux development team. In retrospect, the importance of adding code for new features over adding mundane code for bug fixes, as part of reputation building makes sense. The street cred for fixing old bugs does not seem to be sexy enough; eventhough, some of these bugs could have long term effects on the quality of the Linux OS.
Are there solutions? One solution posited by Morton is to dedicate the entire next release to fixing long standing bugs. Although it is not clear to me how open source developers would react to this constraint. Another solution might try to expand the talent pool by encouraging young, gifted (even student) programmers to work on the bugs. Their motivations might be different from current developers, and any kind of participation might offer enough motivation.
Open source software development is still a fairly new phenomenon and is far from being completely understood. As we see more clearly how motivation factors work and what they produce in the open source production model, it will be increasingly important to document, analyze and learn from these observations. The future sustainability for open source software will rely on learning how to best maintain the developers’ incentives to contribute code. Therefore, we must remind ourselves that the open source development movement is something that must be continuously nurtured. And while we can cite Linux as a success story, the project itself is not on autopilot, nor will it ever be.
sophie is coming!
 Though we haven’t talked much about it here, the Institute is dedicated to practice in addition to the theory we regularly spout here. In July, the Institute will release Sophie, our first piece of software. Sophie is an open-source platform for creating and reading electronic books for the networked environment. It will facilitate the construction of documents that use multimedia and time in ways that are currently difficult, if not impossible, with today’s software. We spend a fair amount of time talking about what electronic books and documents should do on this blog. Hopefully, many of these ideas will be realized in Sophie.
Though we haven’t talked much about it here, the Institute is dedicated to practice in addition to the theory we regularly spout here. In July, the Institute will release Sophie, our first piece of software. Sophie is an open-source platform for creating and reading electronic books for the networked environment. It will facilitate the construction of documents that use multimedia and time in ways that are currently difficult, if not impossible, with today’s software. We spend a fair amount of time talking about what electronic books and documents should do on this blog. Hopefully, many of these ideas will be realized in Sophie.
A beta release for Sophie will be upon us before we know it, and readers of this blog will be hearing (and seeing) more about it in the future. We’re excited about what we’ve seen Sophie do so far; soon you’ll be able to see too. Until then, we can offer you this 13-page PDF that attempts to explain exactly what Sophie is, the problems that it was created to solve, and what it will do. An HTML version of this will be arriving shortly, and there will soon be a Sophie version. There’s also, should you be especially curious, a second 5-page PDF that explains Sophie’s pedigree: a quick history of some of the ideas and software that informed Sophie’s design.
RDF = bigger piles
Last week at a meeting of all the Mellon funded projects I heard a lot of discussion about RDF as a key technology for interoperability. RDF (Resource Description Framework) is a data model for machine readable metadata and a necessary, but not sufficient requirement for the semantic web. On top of this data model you need applications that can read RDF. On top of the applications you need the ability to understand the meaning in the RDF structured data. This is the really hard part: matching the meaning of two pieces of data from two different contexts still requires human judgement. There are people working on the complex algorithmic gymnastics to make this easier, but so far, it’s still in the realm of the experimental.
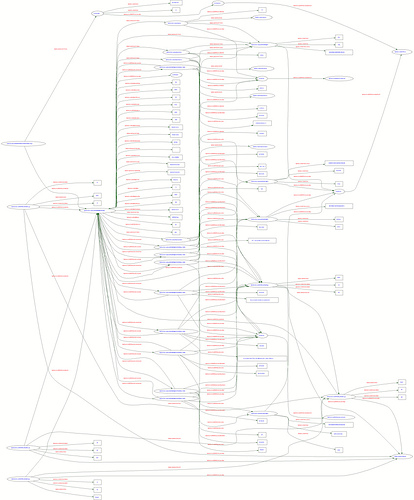
RDF graph of a Flickr Photo
So why pursue RDF? The goal is to make human knowledge, implicit and explicit, machine readable. Not only machine readable, but automatically shareable and reusable by applications that understand RDF. Researchers pursuing the semantic web hope that by precipitating an integrated and interoperable data environment, application developers will be able to innovate in their business logic and provide better services across a range of data sets.
Why is this so hard? Well, partly because the world is so complex, and although RDF is theoretically able to model an entire world’s worth of data relationships, doing it seamlessly is just plain hard. You can spend time developing a RDF representation of all the data in your world, then someone else will come along with their own world, with their own set of data relationships. Being naturally friendly, you take in their data and realize that they have a completely different view of the category “Author,” “Creator,” “Keywords,” etc. Now you have a big, beautiful dataset, with a thousand similar, but not equivalent pieces. The hard part—determining relationships between the data.
We immediately considered how RDF and Sophie would work. RDF importing/exporting in Sophie could provide value by preparing Sophie for integration with other RDF capable applications. But, as always, the real work is figuring out what it is that people could do with this data. Helping users derive meaning from a dataset begs the question: what kind of meaning are we trying to help them discover? A universe of linguistic analysis? Literary theory? Historical accuracy? I think a dataset that enabled all of these would be 90% metadata, and 10% data. This raises another huge issue: entering semantic metadata requires skill and time, and is therefore relatively rare.
In the end, RDF creates bigger, better piles of data—intact with provenance and other unique characteristics derived from the originating context. This metadata is important information that we’d rather hold on to than irrevocably discard, but it leaves us stuck with a labyrinth of data, until we create the tools to guide us out. RDF is ten years old, yet it hasn’t achieved the acceptance of other solutions, like XML Schemas or DTD’s. They have succeeded because they solve limited problems in restricted ways and require relatively simple effort to implement. RDF’s promise is that it will solve much larger problems with solutions that have more richness and complexity; but ultimately the act of determining meaning or negotiating interoperability between two systems is still a human function. The undeniable fact of it remains— it’s easy to put everyone’s data into RDF, but that just leaves the hard part for last.