
In 2005, Jean-Noël Jeanneney, the President of the Bibliothè que Nationale (France’s equivalent of the Library of Congress) wrote one of the most trenchant critiques of Google’s intention to digitize millions of books from a number of major libraries. Jeanneney expanded on his original essay and this past October, The University of Chicago Press published a translation of Google and the Myth of Universal Knowledge: A View from Europe. In this December’s D-Lib Magazine, there’s a superb precis and analysis of Jeanneney’s book by Dave Bearman.
Category Archives: google
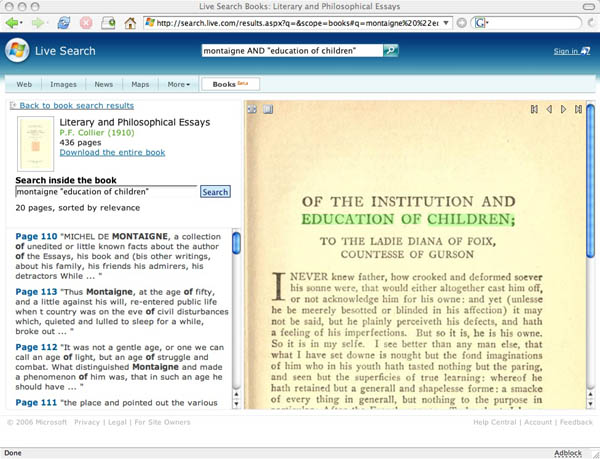
microsoft launches live search books
Windows Live Search Books, Microsoft’s answer to Google Book Search, is officially up and running and looks and feels pretty much the same as its nemesis. Being a Microsoft product, the interface is clunkier, and they have a bit of catching up to do in terms of navigation and search options. The one substantive difference is that Live Search is mostly limited to out-of-copyright books — i.e. pre-19231927 editions of public domain works. So the little they do have in there is fully accessible, with PDFs available for download. Like Google’s public domain books, however, the scans are of pretty poor quality, and not searchable. Readers point out that Microsoft, unlike Google, does in fact include a layer of low-quality but entirely searchable OCR text in its public domain downloads.
no, dammit that’s not what i meant . . . .
I had a very interesting discussion in London the other day with Seb Mary, a brilliant young woman who is exploring ways of using the online world to encourage new forms of community in the offline world. Mary’s most exciting initiatives, which are quite relevant to our interests here at the institute, are still under wraps and i promised not to write about them yet, but she did mention having coined the phrase “offline social software.” Amazingly when i typed the phrase into Google i got back “Did you mean “online social software.” Is Google trying to tell us something? Is the very concept of an offline existence unthinkable in the Googlesphere?
brewster kahle on the google book search “nightmare”

“Pretty much Google is trying to set themselves up as the only place to get to these materials; the only library; the only access. The idea of having only one company control the library of human knowledge is a nightmare.”
From a video interview with Elektrischer Reporter (click image to view).
(via Google Blogoscoped)
google makes slight improvements to book search interface
Google has added a few interface niceties to its Book Search book viewer. It now loads multiple pages at a time, giving readers the option of either scrolling down or paging through left to right. There’s also a full screen reading mode and a “more about this book” link taking you to a profile page with links to related titles plus references and citations from other books or from articles in Google Scholar. Also on the profile page is a searchable keyword cluster of high-incidence names or terms from the text.
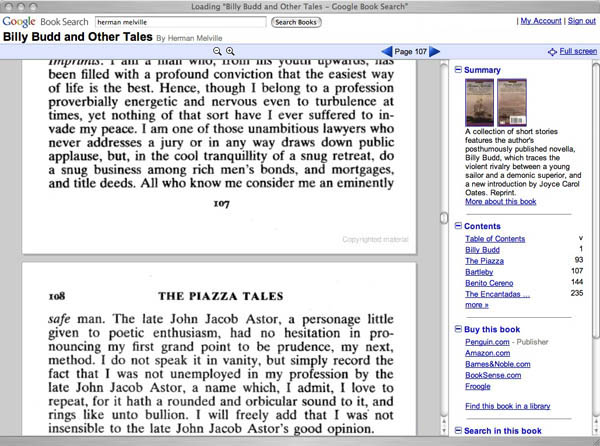
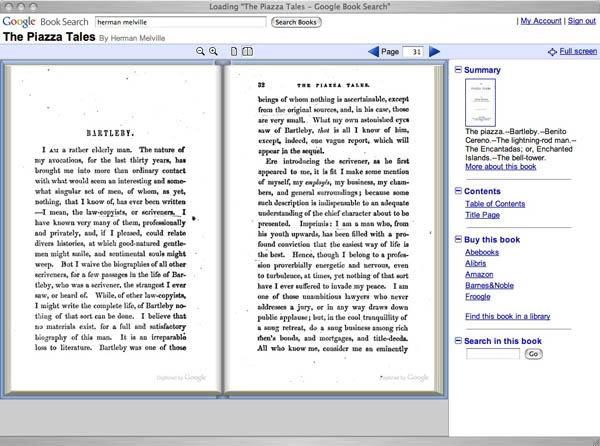
Above is the in-copyright Signet Classic edition of Billy Budd and Other Tales by Melville, which contains only a limited preview of the text. You can also view the entire original 1856 edition of Piazza Tales as scanned from the Stanford Library. Public domain editions like this one can now be viewed with facing pages.
Still a conspicuous lack of any annotation or social reading tools.
terrain as browsing mechanism
Ben’s post last week, book as terrain, about converting any image to an interactive map with hotspots contained a link to a blog which collects info about all sorts of google map mashups. Ben’s post was about using book pages as geographic jumping-off points. However, as i read the endlessly fascinating list of other sorts of mashups it occurred to me that in addition to “book as terrain” we could also look at the idea of “Google map mashups” as a genuinely new form of expression. As I read through the wonderfully annotated list I realized that they cover the full gamut of subjects you would find in a bookstore . . . . Fiction, Non-Fiction, Travel, History, Sports, Games, Religion, Personal Growth, and Crime.
It’s interesting to realize that as our experience moves relentlessly into the virtual domain, that geography, which in the past was firmly rooted in the “real,” increasingly becomes the mechanism for organizing our activiites in virtual space.
book as terrain
People have done all sorts of interesting things with Google maps, but this one I particularly like. Maplib lets you upload any image (the larger and higher res the better) into the Google map interface, turning the picture into a draggable, zoomable and annotatable terrain — a crude mashup tool that nonetheless suggests new spacial ways of navigating text.
I did a quick and dirty image mapping of W.H. Auden’s “Musee des Beaux Arts” onto Breughel’s “Landscape with the Fall of Icarus,” casting the shepherd as poet. Click the markers and then the details links to read the poem (hint: start with the shepherd).
As you can see, they give you the code to embed image maps on other sites. You can post comments on the individual markers right here on if:book, or if you go to the Maplib site itself you can add your own markers.
I quite like this one that someone uploaded of a southerly view of the Italian peninsula (unfortunately it seems to start larger images off-center):
And here’s an annotated Korean barbecue (yum):
google aquires jotspot

Adding wikis to its evolving online office suite.
cs monitor on online books and collaborative writing
In which GAM3R 7H3ORY is discussed at length with some really smart comments by our own Jesse Wilbur. Also covered: Google’s new Docs & Spreadsheets online office suite, Wikipedia, and Larry Sanger’s Wikipedia offshoot, Citizendium.
microsoft steps up book digitization
Back in June, Microsoft struck deals with the University of California and the University of Toronto to scan titles from their nearly 50 million (combined) books into its Windows Live Book Search service. Today, the Guardian reports that they’ve forged a new alliance with Cornell and are going to step up their scanning efforts toward a launch of the search portal sometime toward the beginning of next year. Microsoft will focus on public domain works, but is also courting publishers to submit in-copyright books.
Making these books searchable online is a great thing, but I’m worried by the implications of big coprorations building proprietary databases of public domain works. At the very least, we’ll need some sort of federated book search engine that can leap the walls of these competing services, matching text queries to texts in Google, Microsoft and the Open Content Alliance (which to my understanding is mostly Microsoft anyway).
But more important, we should get to work with OCR scanners and start extracting the texts to build our own databases. Even when they make the files available, as Google is starting to do, they’re giving them to us not as fully functioning digital texts (searchable, remixable), but as strings of snapshots of the scanned pages. That’s because they’re trying to keep control of the cultural DNA scanned from these books — that’s the value added to their search service.
But the public domain ought to be a public trust, a cultural infrastructure that is free to all. In the absence of some competing not-for-profit effort, we should at least start thinking about how we as stakeholders can demand better access to these public domain works. Microsoft and Google are free to scan them, and it’s good that someone has finally kickstarted a serious digitization campaign. It’s our job to hold them accountable, and to make sure that the public domain doesn’t get redefined as the semi-public domain.