Think you’ve got an authoritative take on a subject? Write up an article, or “knol,” and see how the Web judgeth. If it’s any good, you might even make a buck.
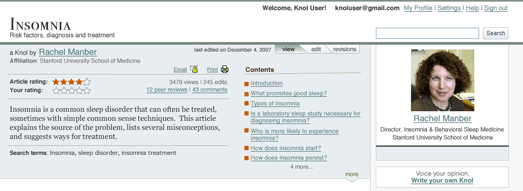
Google’s new encyclopedia will go head to head with Wikipedia in the search rankings, though in format it more resembles other ad-supported, single-author info sources like the About.com or Squidoo. The knol-verse (how the hell do we speak of these things as a whole?) will be a Darwinian writers’ market where the fittest knols rise to the top. Anyone can write one. Google will host it for free. Multiple knols can compete on a single topic. Readers can respond to and evaluate knols through simple community rating tools. Content belongs solely to the author, who can license it in any way he/she chooses (all rights reserved, Creative Commons, etc.). Authors have the option of having contextual ads run to the side, revenues from which are shared with Google. There is no vetting or editorial input from Google whatsoever.
Except… Might not the ads exert their own subtle editorial influence? In this entrepreneurial writers’ fray, will authors craft their knols for AdSense optimization? Will they become, consciously or not, shills for the companies that place the ads (I’m thinking especially of high impact topic areas like health and medicine)? Whatever you may think of Wikipedia, it has a certain integrity in being ad-free. The mission is clear and direct: to build a comprehensive free encyclopedia for the Web. The range of content has no correlation to marketability or revenue potential. It’s simply a big compendium of stuff, the only mention of money being a frank electronic tip jar at the top of each page. The Googlepedia, in contrast, is fundamentally an advertising platform. What will such an encyclopedia look like?
In the official knol announcement, Udi Manber, a VP for engineering at Google, explains the genesis of the project: “The challenge posed to us by Larry, Sergey and Eric was to find a way to help people share their knowledge. This is our main goal.” You can see embedded in this statement all the trademarks of Google’s rhetoric: a certain false humility, the pose of incorruptible geek integrity and above all, a boundless confidence that every problem, no matter how gray and human, has a technological fix. I’m not saying it’s wrong to build a business, nor that Google is lying whenever it talks about anything idealistic, it’s just that time and again Google displays an astonishing lack of self-awareness in the way it frames its services -? a lack that becomes especially obvious whenever the company edges into content creation and hosting. They tend to talk as though they’re building the library of Alexandria or the great Encyclopédie, but really they’re describing an advanced advertising network of Google-exclusive content. We shouldn’t allow these very different things to become as muddled in our heads as they are in theirs. You get a worrisome sense that, like the Bushies, the cheerful software engineers who promote Google’s products on the company’s various blogs truly believe the things they’re saying. That if we can just get the algorithm right, the world can bask in the light of universal knowledge.
The blogosphere has been alive with commentary about the knol situation throughout the weekend. By far the most provocative thing I’ve read so far is by Anil Dash, VP of Six Apart, the company that makes the Movable Type software that runs this blog. Dash calls out this Google self-awareness gap, or as he puts it, its lack of a “theory of mind”:
Theory of mind is that thing that a two-year-old lacks, which makes her think that covering her eyes means you can’t see her. It’s the thing a chimpanzee has, which makes him hide a banana behind his back, only taking bites when the other chimps aren’t looking.
Theory of mind is the awareness that others are aware, and its absence is the weakness that Google doesn’t know it has. This shortcoming exists at a deep cultural level within the organization, and it keeps manifesting itself in the decisions that the company makes about its products and services. The flaw is one that is perpetuated by insularity, and will only be remedied by becoming more open to outside ideas and more aware of how people outside the company think, work and live.
He gives some examples:
Connecting PageRank to economic systems such as AdWords and AdSense corrupted the meaning and value of links by turning them into an economic exchange. Through the turn of the millennium, hyperlinking on the web was a social, aesthetic, and expressive editorial action. When Google introduced its advertising systems at the same time as it began to dominate the economy around search on the web, it transformed a basic form of online communication, without the permission of the web’s users, and without explaining that choice or offering an option to those users.
He compares the knol enterprise with GBS:
Knol shares with Google Book Search the problem of being both indexed by Google and hosted by Google. This presents inherent conflicts in the ranking of content, as well as disincentives for content creators to control the environment in which their content is published. This necessarily disadvantages competing search engines, but more importantly eliminates the ability for content creators to innovate in the area of content presentation or enhancement. Anything that is written in Knol cannot be presented any better than the best thing in Knol. [his emphasis]
And lastly concludes:
An awareness of the fact that Google has never displayed an ability to create the best tools for sharing knowledge would reveal that it is hubris for Google to think they should be a definitive source for hosting that knowledge. If the desire is to increase knowledge sharing, and the methods of compensation that Google controls include traffic/attention and money/advertising, then a more effective system than Knol would be to algorithmically determine the most valuable and well-presented sources of knowledge, identify the identity of authorites using the same journalistic techniques that the Google News team will have to learn, and then reward those sources with increased traffic, attention and/or monetary compensation.
For a long time Google’s goal was to help direct your attention outward. Increasingly we find that they want to hold onto it. Everyone knows that Wikipedia articles place highly in Google search results. Makes sense then that they want to capture some of those clicks and plug them directly into the Google ad network. But already the Web is dominated by a handful of mega sites. I get nervous at the thought that www.google.com could gradually become an internal directory, that Google could become the alpha and omega, not only the start page of the Internet but all the destinations.
It will be interesting to see just how and to what extent knols start creeping up the search results. Presumably, they will be ranked according to the same secret metrics that measure all pages in Google’s index, but given the opacity of their operations, who’s to say that subtle or unconscious rigging won’t occur? Will community ratings factor in search rankings? That would seem to present a huge conflict of interest. Perhaps top-rated knols will be displayed in the sponsored links area at the top of results pages. Or knols could be listed in order of community ranking on a dedicated knol search portal, providing something analogous to the experience of searching within Wikipedia as opposed to finding articles through external search engines. Returning to the theory of mind question, will Google develop enough awareness of how it is perceived and felt by its users to strike the right balance?
One last thing worth considering about the knol -? apart from its being possibly the worst Internet neologism in recent memory -? is its author-centric nature. It’s interesting that in order to compete with Wikipedia Google has consciously not adopted Wikipedia’s model. The basic unit of authorial action in Wikipedia is the edit. Edits by multiple contributors are combined, through a complicated consensus process, into a single amalgamated product. On Google’s encyclopedia the basic unit is the knol. For each knol (god, it’s hard to keep writing that word) there is a one to one correspondence with an individual, identifiable voice. There may be multiple competing knols, and by extension competing voices (you have this on Wikipedia too, but it’s relegated to the discussion pages).
Viewed in this way, Googlepedia is perhaps a more direct rival to Larry Sanger’s Citizendium, which aims to build a more authoritative Wikipedia-type resource under the supervision of vetted experts. Citizendium is a strange, conflicted experiment, a weird cocktail of Internet populism and ivory tower elitism -? and by the look of it, not going anywhere terribly fast. If knols take off, could they be the final nail in the coffin of Sanger’s awkward dream? Bryan Alexander wonders along similar lines.
While not explicitly employing Sanger’s rhetoric of “expert” review, Google seems to be banking on its commitment to attributed solo authorship and its ad-based incentive system to lure good, knowledgeable authors onto the Web, and to build trust among readers through the brand-name credibility of authorial bylines and brandished credentials. Whether this will work remains to be seen. I wonder… whether this system will really produce quality. Whether there are enough checks and balances. Whether the community rating mechanisms will be meaningful and confidence-inspiring. Whether self-appointed experts will seem authoritative in this context or shabby, second-rate and opportunistic. Whether this will have the feeling of an enlightened knowledge project or of sleezy intellectual link farming (or something perfectly useful in between).
The feel of a site -? the values it exudes -? is an important factor though. This is why I like, and in an odd way trust Wikipedia. Trust not always to be correct, but to be transparent and to wear its flaws on its sleeve, and to be working for a higher aim. Google will probably never inspire that kind of trust in me, certainly not while it persists in its dangerous self-delusions.
A lot of unknowns here. Thoughts?