
Today Google unveiled a major extension of its news search service, expanding into periodical archives that stretch back to the mid-18th century. Most of the articles are pay downloads, or pay-per-view, and are offered by Google through licensing agreements with newspapers and existing document retrieval services including The New York Times Co., The Washington Post Co., The Wall Street Journal, Reed Elsevier, LexisNexis and Factiva. Google won’t actually host content or handle payments, it simply presents items with titles, brief excerpts and ordering information. Google also crawls free archives already on the web and mixes these in, and (a nice touch) links all search results to “related web pages,” plugging keywords into a general web search. Google won’t run adds in this service, at least for now. More coverage here and here.
This is a fine service, but it only underscores the need for a non-commercial alternative. Much of the material here is public domain, but is provided through commercial services. Google simply adds a new web-integrated layer. Anyone who believes that the public domain ought to be fully accessible to all should be thinking bigger than Google.
Author Archives: ben vershbow
google flirts with image tagging
 Ars Technica reports that Google has begun outsourcing, or “crowdsourcing,” the task of tagging its image database by asking people to play a simple picture labeling game. The game pairs you with a randomly selected online partner, then, for 90 seconds, runs you through a sequence of thumbnail images, asking you to add as many labels as come to mind. Images advance whenever you and your partner hit upon a match (an agreed-upon tag), or when you agree to take a pass.
Ars Technica reports that Google has begun outsourcing, or “crowdsourcing,” the task of tagging its image database by asking people to play a simple picture labeling game. The game pairs you with a randomly selected online partner, then, for 90 seconds, runs you through a sequence of thumbnail images, asking you to add as many labels as come to mind. Images advance whenever you and your partner hit upon a match (an agreed-upon tag), or when you agree to take a pass.
I played a few rounds but quickly grew tired of the bland consensus that the game encourages. Matches tend to be banal, basic descriptors, while anything tricky usually results in a pass. In other words, all the pleasure of folksonomies — splicing one’s own idiosyncratic sense of things with the usually staid task of classification — is removed here. I don’t see why they don’t open the database up to much broader tagging. Integrate it with the image search and harvest a bigger crop of metadata.
Right now, it’s more like Tom Sawyer tricking the other boys into whitewashing the fence. Only, I don’t think many will fall for this one because there’s no real incentive to participation beyond a halfhearted points system. For every matched tag, you and your partner score points, which accumulate in your Google account the more you play. As far as I can tell, though, points don’t actually earn you anything apart from a shot at ranking in the top five labelers, which Google lists at the end of each game. Whitewash, anyone?
In some ways, this reminded me of Amazon’s Mechanical Turk, an “artificial artificial intelligence” service where anyone can take a stab at various HIT’s (human intelligence tasks) that other users have posted. Tasks include anything from checking business hours on restaurant web sites against info in an online directory, to transcribing podcasts (there are a lot of these). “Typically these tasks are extraordinarily difficult for computers, but simple for humans to answer,” the site explains. In contrast to the Google image game, with the Mechanical Turk, you can actually get paid. Fees per HIT range from a single penny to several dollars.
I’m curious to see whether Google goes further with tagging. Flickr has fostered the creation of a sprawling user-generated taxonomy for its millions of images, but the incentives to tagging there are strong and inextricably tied to users’ personal investment in the production and sharing of images, and the building of community. Amazon, for its part, throws money into the mix, which (however modest the sums at stake) makes Mechanical Turk an intriguing, and possibly entertaining, business experiment, not to mention a place to make a few extra bucks. Google’s experiment offers neither, so it’s not clear to me why people should invest.
on business models in web publishing

Here at the Institute, we’re generally more interested in thinking up new forms of publishing than in figuring out how to monetize them. But one naturally perks up at news of big money being made from stuff given away for free. Doc Searls points to a few items of such news.
First, that latest iteration of the American dream: blogging for big bucks, or, the self-made media mogul. Yes, a few have managed to do it, though I don’t think they should be taken as anything more than the exceptions that prove the rule that most blogs are smaller scale efforts in an ecology of niches, where success is non-monetary and more of the “nanofame” variety that iMomus, David Weinberger and others have talked about (where everyone is famous to fifteen people). But there is that dazzling handful of popular bloggers that rival the mass media outlets, and they’re raking in tens, if not hundreds, of thousands of dollars in ad revenues.
Some sites mentioned in the article:
— TechCrunch: “$60,000 in ad revenue every month” (not surprising — its right column devoted to sponsors is one of the widest I’ve seen)
— Boing Boing: “on track to gross an estimated $1 million in ad revenue this year”
— paidContent.org: over a million a year
— Fark.com: “on pace to become a multimillion-dollar property.
Then, somewhat surprisingly, is The New York Times. Handily avoiding the debacle predicted a year ago by snarky bloggers like myself when the paper decided to relocate its op-ed columnists and other distinctive content behind a pay wall, the Times has pulled in $9 million from nearly 200,000 web-exclusive Times Select subscribers, while revenues from the Times-owned About.com continue to skyrocket. There’s a feeling at the company that they’ve struck a winning formula (for now) and will see how long they can ride it:
When I ask if TimesSelect has been successful enough to suggest that more material be placed behind the wall, Nisenholtz [senior vice president for digital operations] replies, “The strategy isn’t to move more content from the free site to the pay site; we need inventory to sell to advertisers. The strategy is to create a more robust TimesSelect” by using revenue from the service to pay for more unique content. “We think we have the right formula going,” he says. “We don’t want to screw it up.”
***Subsequent thought: I’m not so sure. Initial indicators may be good, but I still think that the pay wall is a ticket to irrelevance for the Times’ columnists. Their readership is large and (for now) devoted enough to maintain the modestly profitable fortress model, but I think we’ll see it wither over time.***
Also, in the Times, there’s this piece about ad-supported wiki hosting sites like Wikia, Wetpaint, PBwiki or the swiftly expanding WikiHow, a Wikipedia-inspired how-to manual written and edited by volunteers. Whether or not the for-profit model is ultimately compatible with the wiki work ethic remains to be seen. If it’s just discrete ads in the margins that support the enterprise, then contributors can still feel to a significant extent that these are communal projects. But encroach further and people might begin to think twice about devoting their time and energy.
***Subsequent thought 2: Jesse made an observation that makes me wonder again whether the Times Company’s present success (in its present framework) may turn out to be short-lived. These wiki hosting networks are essentially outsourcing, or “crowdsourcing” as the latest jargon goes, the work of the hired About.com guides. Time will tell which is ultimately the more sustainable model, and which one will produce the better resource. Given what I’ve seen on About.com, I’d place my bets on the wikis. The problem? You, or your community, never completely own your site, so you’re locked into amateur status. With Wikipedia, that’s the point. But can a legacy media company co-opt so many freelancers without pay? These are drastically different models. We’re probably not dealing with an either/or here.***
We’ve frequently been asked about the commercial potential of our projects — how, for instance, something like GAM3R 7H30RY might be made to make money. The answer is we don’t quite know, though it should be said that all of our publishing experiments have led to unexpected, if modest, benefits — bordering on the financial — for their authors. These range from Alex selling some of his paintings to interested commenters at IT IN place, to Mitch gradually building up a devoted readership for his next book at Without Gods while still toiling away at the first chapter, to McKenzie securing a publishing deal with Harvard within days of the Chronicle of Higher Ed. piece profiling GAM3R 7H30RY (GAM3R 7H30RY version 1.2 will be out this spring, in print).
Build up the networks, keep them open and toll-free, and unforseen opportunities may arise. It’s long worked this way in print culture too. Most authors aren’t making a living off the sale of their books. Writing the book is more often an entree into a larger conversation — from the ivory tower to the talk show circuit, and all points in between. With the web, however, we’re beginning to see the funnel reversed: having the conversation leads to writing the book. At least in some cases. At this point it’s hard to trace what feeds into what. So many overlapping conversations. So many overlapping economies.
grand theft auto flipped in new coke ad
This apparently made the blog rounds recently, but I just saw it for the first time tonight in a movie theater and was mighty impressed:
And a twist on this: check out this Washington Post article on live ads in video games.
library wisdom
Bob and I have been impressed with what we’ve been reading on a series of sites maintained by Joyce Valenza, a teacher-Librarian at the Springfield Township High School Library in Erdenheim, Pennsylvania. Of particular interest is a chart she’s put together entitled “30 Years of Information and Educational Change: How should our practice respond?” which records the dramatic technological shifts that have taken place since she began studying library science nearly three decades ago, and how her thinking has evolved:
I graduated with an MLS in 1977 and had to return and redo most of the credits in 1987/1988 to get education credentials. While I learned programming the first time around and personal computer applications the second time around, the rate of change has dramatically altered the landscape.
I see an urgent need for librarians to retool. We cannot expect to assume a leadership role in information technology and instruction, we cannot claim any credibility with students, faculty, or administrators if we do not recognize and thoughtfully exploit the paradigm shift of the past two years. Retooling is essential for the survival of the profession.
The role of the librarian has traditionally to guide the user into a dense grove of knowledge, instructing them how best to penetrate, navigate and reference a relatively stable corpus. But with the explosion of personal computers and networks comes the explosion of the library. The librarian becomes a strategic advisor at the gateway to a much larger and continually shifting array of resources and tools that extends well beyond the physical boundaries of the library. The user no longer needs to be guided inward, but guided outward, and in multiple directions. The librarian in an academic or school setting must help students and scholars to match up the right materials with the right modes of communication, while also fostering a critical and ethical outlook in a world awash in information. The librarian is more crucial than ever.
The physical space of the library is still vital too, Valenza argues, and nowhere is this better conveyed than in this charming “virtual library” page she has constructed for the library’s home page (that’s her standing by the reference desk):
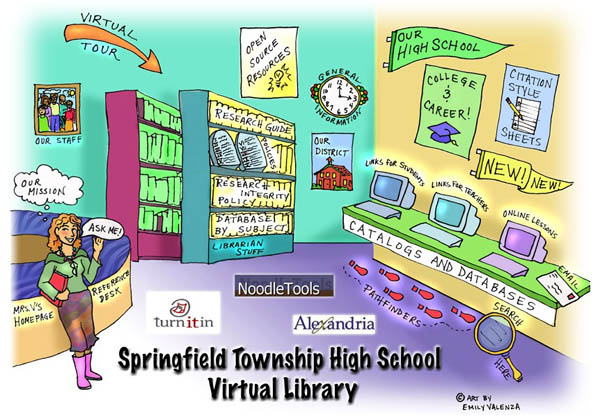
It seems almost too obvious to use the physical library as an interface, but I was immediately struck by how intuitive and useful this page is, and how, so simply and with such spirit, it creates an almost visceral link between the physical library and its online dimensions.
(Also check out Valenza’s blog, NeverEnding Search.)
google offers public domain downloads
Google announced today that it has made free downloadable PDFs available for many of the public domain books in its database. This is a good thing, but there are several problems with how they’ve done it. The main thing is that these PDFs aren’t actually text, they’re simply strings of images from the scanned library books. As a result, you can’t select and copy text, nor can you search the document, unless, of course, you do it online in Google. So while public access to these books is a big win, Google still has us locked into the system if we want to take advantage of these books as digital texts.
A small note about the public domain. Editions are key. A large number of books scanned so far by Google have contents in the public domain, but are in editions published after the cut-off (I think we’re talking 1923 for most books). Take this 2003 Signet Classic edition of the Darwin’s The Origin of Species. Clearly, a public domain text, but the book is in “limited preview” mode on Google because the edition contains an introduction written in 1958. Copyright experts out there: is it just this that makes the book off limits? Or is the whole edition somehow copyrighted?
Other responses from Teleread and Planet PDF, which has some detailed suggestions on how Google could improve this service.
discursions II: networked architecture, a networked book
I’m pleased to announce a new networked book project the Institute will begin working on this fall. “Discursions, II” will explore the history and influence of the Architecture Machine Group, the amazing research collective of the late 60s and 70s that later morphed into the MIT Media Lab. The book will be developed in collaboration with Kazys Varnelis, an architectural historian whom we met this past year at the Annenberg Center at USC, when he was a visiting fellow leading the “Networked Publics” research project.

As its name suggests, the Architecture Machine Group was originally formed to explore how computers might be used in the design of architecture. From there, it went on to make history, inventing many of the mechanisms and metaphors of human-machine interaction that we live, work and play with to this day. Lately, Kazys’ focus has been on contemporary architecture and urbanism in the context of network technologies, and how machine-mediated interactions are becoming a key feature of human environments. So he’s pretty uniquely positioned to weave together the diverse threads of this history. Most important from the Institute’s perspective, he’s interested in playing around with the form and feel of publication.
And good news. Kazys recently resettled here on the east coast, where he will be heading up the new Network Architecture Lab (NetLab) at Columbia’s Graduate School of Architecture, Planning, and Preservation. One of the lab’s first projects will be this joint venture with the Institute. Unlike Without Gods and GAM3R 7H30RY, both of which are print-network hybrids, “Discursions, II” will grow one hundred percent on the network, beginning from its initial seeds: a dozen videos of seminal ARCMac demos, originally published on a video disc called “Discursions”. The book will also go much further into collaborative methods of work, and into blurring the boundaries of genre and media form, employing elements of documentary film, textual narrative, and oral history (and other strategies yet to be determined).
From the NetLab press release (AUDC, mentioned below, is Kazys’ nonprofit architectural collective):
Formed in 2001, AUDC [Architecture Urbanism Design Collaborative] specializes in research as a form of practice. The AUDC Network Architecture Lab is an experimental unit at Columbia University that embraces the studio and the seminar as venues for architectural analysis and speculation, exploring new forms of research through architecture, text, new media design, film production and environment design.
Specifically, the Network Architecture Lab investigates the impact of computation and communications on architecture and urbanism. What opportunities do programming, telematics, and new media offer architecture? How does the network city affect the building? Who is the subject and what is the object in a world of networked things and spaces? How do transformations in communications reflect and affect the broader socioeconomic milieu? The NetLab seeks to both document this emergent condition and to produce new sites of practice and innovative working methods for architecture in the twenty-first century. Using new media technologies, the lab aims to develop new interfaces to both physical and virtual space. This unit is consciously understood as an interdisciplinary entity, establishing collaborative relationships with other centers both at Columbia and at other institutions.
The NetLab begins operations in September 2006 with “Discursions, II” an exploration of history of architecture, computation, and new media interfaces at the Architecture Machine Group at MIT done in collaboration with the Institute for the Future of the Book.
For a better idea of Kazys’ interests and voice, take a look at this fascinating and wide-ranging interview published recently on BLDGBLOG. Here, he talks a bit more about what we’re hoping to do with the book:
The goal, then, is to create a new form of media that we’re calling the Networked Book. It’s a multimedia book, if you will, that can evolve on the internet and grow over time. We’re now hoping to get the original players involved, and to get commentary in there. The project won’t be just the voice of one author but the voices of many, and it won’t be just one form of text but, rather, all sorts of media. We don’t really know where it will go, in fact, but that’s part of the project: to let the material take us; to examine the past, present, and future of the computer interface; and to do something that’s really bold. It’s not that we don’t know what we’re doing [laughter] – it’s that we have a wide variety of options.
Congratulatons, Kazys, on the founding of the NetLab. We can’t wait to move forward with this project.
showtiming our libraries

 Google’s contract with the University of California to digitize library holdings was made public today after pressure from The Chronicle of Higher Education and others. The Chronicle discusses some of the key points in the agreement, including the astonishing fact that Google plans to scan as many as 3,000 titles per day, and its commitment, at UC’s insistence, to always make public domain texts freely and wholly available through its web services.
Google’s contract with the University of California to digitize library holdings was made public today after pressure from The Chronicle of Higher Education and others. The Chronicle discusses some of the key points in the agreement, including the astonishing fact that Google plans to scan as many as 3,000 titles per day, and its commitment, at UC’s insistence, to always make public domain texts freely and wholly available through its web services.
But there are darker revelations as well, and Jeff Ubois, a TV-film archivist and research associate at Berkeley’s School of Information Management and Systems, hones in on some of these on his blog. Around the time that the Google-UC deal was first announced, Ubois compared it to Showtime’s now-infamous compact with the Smithsonian, which caused a ripple of outrage this past April. That deal, the details of which are secret, basically gives Showtime exclusive access to the Smithsonian’s film and video archive for the next 30 years.
The parallels to the Google library project are many. Four of the six partner libraries, like the Smithsonian, are publicly funded institutions. And all the agreements, with the exception of U. Michigan, and now UC, are non-disclosure. Brewster Kahle, leader of the rival Open Content Alliance, put the problem clearly and succinctly in a quote in today’s Chronicle piece:
We want a public library system in the digital age, but what we are getting is a private library system controlled by a single corporation.
He was referring specifically to sections of this latest contract that greatly limit UC’s use of Google copies and would bar them from pooling them in cooperative library systems. I vocalized these concerns rather forcefully in my post yesterday, and may have gotten a couple of details wrong, or slightly overstated the point about librarians ceding their authority to Google’s algorithms (some of the pushback in comments and on other blogs has been very helpful). But the basic points still stand, and the revelations today from the UC contract serve to underscore that. This ought to galvanize librarians, educators and the general public to ask tougher questions about what Google and its partners are doing. Of course, all these points could be rendered moot by one or two bad decisions from the courts.
the children’s machine

That’s now the name of the $100 laptop, or one laptop per child. Fits up to six children inside.
Why is it that the publicity images of these machines are always like this? Ghostly showroom white and all the kids crammed inside. What might it mean? I get the feeling that we’re looking at the developers’ fantasy. All this well-intentioned industry and aspiration poured into these little day-glo machines. But totally decontextualized, in a vacuum.

This ealier one was supposed to show poor, brown hands reaching for the stars, but it looked more to me like children sinking in quicksand.
Indian Education Secretary Sudeep Banerjee, explaining last month why his country would not be placing an order for Negroponte’s machines, put it more bluntly. He called the laptops “pedagogically suspect.”
ADDENDUM
An exhange in the comments below made me want to clarify my position here. Bleak humor aside, I really hope that the laptop project succeeds. From the little I’ve heard, it appears that the developers have some really interesting ideas about the kind of software that’ll go into these things.
Dan, still reeling from three days of Wikimania earlier this month, as well as other meetings concerning OLPC, relayed the fact that the word processing software being bundled into the laptops will all be wiki-based, putting the focus on student collaboration over mesh networks. This may not sound like such a big deal, but just take a moment to ponder the implications of having all class writing assignments being carried out wikis. The different sorts of skills and attitudes that collaborating on everything might nurture. There a million things that could go wrong with the One Laptop Per Child project, but you can’t accuse its developers of lacking bold ideas about education.
Still, I’m skeptical that those ideas will connect successfully to real classroom situations. For instance, we’re not really hearing anything about teacher training. One hopes that community groups will spring into action to help develop and implement new pedagogical strategies that put the Children’s Machines to good use. But can we count on this happening? I’m afraid this might be the fatal gap in this otherwise brilliant project.
librarians, hold google accountable
I’m quite disappointed by this op-ed on Google’s library intiative in Tuesday’s Washington Post. It comes from Richard Ekman, president of the Council of Independent Colleges, which represents 570 independent colleges and universities in the US (and a few abroad). Generally, these are mid-tier schools — not the elite powerhouses Google has partnered with in its digitization efforts — and so, being neither a publisher, nor a direct representative of one of the cooperating libraries, I expected Ekman might take a more measured approach to this issue, which usually elicits either ecstatic support or vociferous opposition. Alas, no.

To the opposition, namely, the publishing industry, Ekman offers the usual rationale: Google, by digitizing the collections of six of the english-speaking world’s leading libraries (and, presumably, more are to follow) is doing humanity a great service, while still fundamentally respecting copyrights — so let’s not stand in its way. With Google, however, and with his own peers in education, he is less exacting.
The nation’s colleges and universities should support Google’s controversial project to digitize great libraries and offer books online. It has the potential to do a lot of good for higher education in this country.
Now, I’ve poked around a bit and located the agreement between Google and the U. of Michigan (freely available online), which affords a keyhole view onto these grand bargains. Basically, Google makes scans of U. of M.’s books, giving them images and optical character recognition files (the texts gleaned from the scans) for use within their library system, keeping the same for its own web services. In other words, both sides get a copy, both sides win.
If you’re not Michigan or Google, though, the benefits are less clear. Sure, it’s great that books now come up in web searches, and there’s plenty of good browsing to be done (and the public domain texts, available in full, are a real asset). But we’re in trouble if this is the research tool that is to replace, by force of market and by force of users’ habits, online library catalogues. That’s because no sane librarian would outsource their profession to an unaccountable private entity that refuses to disclose the workings of its system — in other words, how does Google’s book algorithm work, how are the search results ranked? And yet so many librarians are behind this plan. Am I to conclude that they’ve all gone insane? Or are they just so anxious about the pace of technological change, driven to distraction by fears of obsolescence and diminishing reach, that they are willing to throw their support uncritically behind the company, who, like a frontier huckster, promises miracle cures and grand visions of universal knowledge?

We may be resigned to the steady takeover of college bookstores around the country by Barnes and Noble, but how do we feel about a Barnes and Noble-like entity taking over our library systems? Because that is essentially what is happening. We ought to consider the Google library pact as the latest chapter in a recent history of consolidation and conglomeratization in publishing, which, for the past few decades (probably longer, I need to look into this further) has been creeping insidiously into our institutions of higher learning. When Google struck its latest deal with the University of California, and its more than 100 libraries, it made headlines in the technology and education sections of newspapers, but it might just as well have appeared in the business pages under mergers and acquisitions.
So what? you say. Why shouldn’t leaders in technology and education seek each other out and forge mutually beneficial relationships, relationships that might yield substantial benefits for large numbers of people? Okay. But we have to consider how these deals among titans will remap the information landscape for the rest of us. There is a prevailing attitude today, evidenced by the simplistic public debate around this issue, that one must accept technological advances on the terms set by those making the advances. To question Google (and its collaborators) means being labeled reactionary, a dinosaur, or technophobic. But this is silly. Criticizing Google does not mean I am against digital libraries. To the contrary, I am wholeheartedly in favor of digital libraries, just the right kind of digital libraries.
What good is Google’s project if it does little more than enhance the world’s elite libraries and give Google the competitive edge in the search wars (not to mention positioning them in future ebook and print-on-demand markets)? Not just our little institute, but larger interest groups like the CIC ought to be voices of caution and moderation, celebrating these technological breakthroughs, but at the same time demanding that Google Book Search be more than a cushy quid pro quo between the powerful, with trickle-down benefits that are dubious at best. They should demand commitments from the big libraries to spread the digital wealth through cooperative web services, and from Google to abide by certain standards in its own web services, so that smaller librarians in smaller ponds (and the users they represent) can trust these fantastic and seductive new resources. But Ekman, who represents 570 of these smaller ponds, doesn’t raise any of these questions. He just joins the chorus of approval.

What’s frustrating is that the partner libraries themselves are in the best position to make demands. After all, they have the books that Google wants, so they could easily set more stringent guidelines for how these resources are to be redeployed. But why should they be so magnanimous? Why should they demand that the wealth be shared among all institutions? If every student can access Harvard’s books with the click of a mouse, than what makes Harvard Harvard? Or Stanford Stanford?
Enlightened self-interest goes only so far. And so I repeat, that’s why people like Ekman, and organizations like the CIC, should be applying pressure to the Harvards and Stanfords, as should organizations like the Digital Library Federation, which the Michigan-Google contract mentions as a possible beneficiary, through “cooperative web services,” of the Google scanning. As stipulated in that section (4.4.2), however, any sharing with the DLF is left to Michigan’s “sole discretion.” Here, then, is a pressure point! And I’m sure there are others that a more skilled reader of such documents could locate. But a quick Google search (acceptable levels of irony) of “Digital Library Federation AND Google” yields nothing that even hints at any negotiations to this effect. Please, someone set me straight, I would love to be proved wrong.
Google, a private company, is in the process of annexing a major province of public knowledge, and we are allowing it to do so unchallenged. To call the publishers’ legal challenge a real challenge, is to misidentify what really is at stake. Years from now, when Google, or something like it, exerts unimaginable influence over every aspect of our informated lives, we might look back on these skirmishes as the fatal turning point. So that’s why I turn to the librarians. Raise a ruckus.
UPDATE (8/25): The University of California-Google contract has just been released. See my post on this.