
You may have noticed that the blog hasn’t been updated much in the last few days. Right now several of us are in far flung places, traveling around the globe for various reasons. We’ll do our best to update you on networked publishing wherever we find it, but it might take just a little longer than normal for us to get to a computer.
Until then, I thought it’d be fun to revisit some old posts. Around the table at work we often feel burdened by the tyranny of the timely post. It’s something that doesn’t leave much room for reflection. I’ve felt that we should find ways to pull up some of the posts that have in some way impacted us and our community the most, so I’ve started with a simple numerical solution: most popular posts (via comment counts) from last year. Here’s a selection:
First, a post that deals with what people commonly think of when they hear electronic book (if they aren’t regularly reading this blog, anyway): first sighting of Sony ebook reader
And then two posts about what we are working towards when we talk about a networked book: defining the networked book: a few thoughts and a list, and small steps toward an n-dimensional reading/writing space.
And three posts on issues we think pertain to the ecology that surrounds networked books:
the evils of photoshop, who owns the network, and AAUP on open access / business as usual?
Monthly Archives: June 2007
stunning views
Amazing. I’ve installed the Photosynth preview on my own machine (sadly it seems to work in IE only on a PC—not surprising, but a little disappointing), and I am zooming around in the Piazza San Marco courtesy of photos shot by a Photosynth Program Manager. The experience is incredible, and totally unique.
There are questions that arise: Is participation something that is voluntary, or is it something more ubiquitous and automatic that will just happen when you upload pictures to the web? (In the case of the preview that I’m running, we can assume it was a Microsoft sponsored trip. But the question is pertinent for future plans.) What are the mechanisms in place to provide privacy? What are the mechanisms to allow for editorializing; for instance, what if I wanted to see only shots taken at night? The images I’m looking at of Saint Mark’s Plaza were all shot by the same person on what looks like the same day with the same camera. How will this work with a different set of images taken with different hands, shutter speeds, attention to details like focus, lighting, foregrounding, etc.? And a larger, geographical and geopolitical question: how were these sites chosen? Will we (the public) be able to contribute models as well as photos so that I can make my city block a photo-navigable space? Or, more importantly, someone in São Paulo can make a map of their city block?
But aside from the questions, this is the most exciting way to view photos from the ‘net that I have ever seen.
cache me if you can
Over at Teleread, David Rothman has a pair of posts about Google’s new desktop RSS reader and a couple of new technologies for creating “offline web applications” (Google Gears and Adobe Apollo), tying them all together into an interesting speculation about the possibility of offline networked books. This would mean media-rich, hypertextual books that could cache some or all of their remote elements and be experienced whole (or close to whole) without a network connection, leveraging the local power of the desktop. Sophie already does this to a limited degree, caching remote movies for a brief period after unplugging.
Electronic reading is usually prey to a million distractions and digressions, but David’s idea suggests an interesting alternative: you take a chunk of the network offline with you for a more sustained, “bounded” engagement. We already do this with desktop email clients and RSS readers, which allow us to browse networked content offline. This could be expanded into a whole new way of reading (and writing) networked books. Having your own copy of a networked document. Seems this should be a basic requirement for any dedicated e-reader worth its salt, to be able to run rich web applications with an “offline” option.
talk at brooklyn college library
If you’re in the New York area, this Wednesday I’ll be giving a talk at an event organized by the Brooklyn College Library called “It’s All About the Book.” Also speaking will be Jason Epstein, one of the all-time great innovators in print publishing, and founder most recently of On Demand Books. Talks will be followed by a tour of “books as art” installations by a number of local artists, curators and librarians. It promises to be an interesting event, well worth the trek to Flatbush.
visual amazon browser
The interface design firm TouchGraph recently released a free visual browsing tool for Amazon’s books, movies, music and electronics inventories. My first thought was, aha, here’s a tool that can generate an image of Bob’s thought experiment, which reimagines The Communist Manifesto as a networked book, connected digitally to all the writings it has influenced and all the commentaries that have been written about it. Alas no.
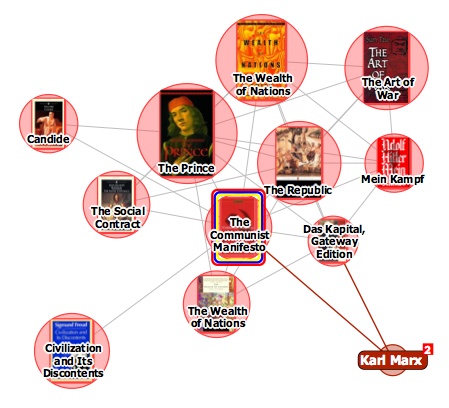
It turns out that relations between items in the TouchGraph clusters are based not on citations across texts but purely on customer purchase patterns, the data that generates the “customers who bought this item also bought” links on Amazon pages. The results, consequently, are a tad shallow. Above you see The Communist Manifesto situated in a small web of political philosophy heavyweights, an image that reveals more about Amazon’s algorithmically derived recommendations than any actual networks of discourse.
TouchGraph has built a nice tool, and I’m sure with further investigation it might reveal interesting patterns in Amazon reading (and buying) behaviors (in the electronics category, it could also come in handy for comparison shopping). But I’d like to see a new verion that factors in citation indexes for books – data that Amazon already provides for many of its titles anyway. They could also look at user-supplied tags, Listmania lists, references from reader reviews etc. And perhaps with the option to view clusters across media types, not simply broken down into book, movie and music categories.