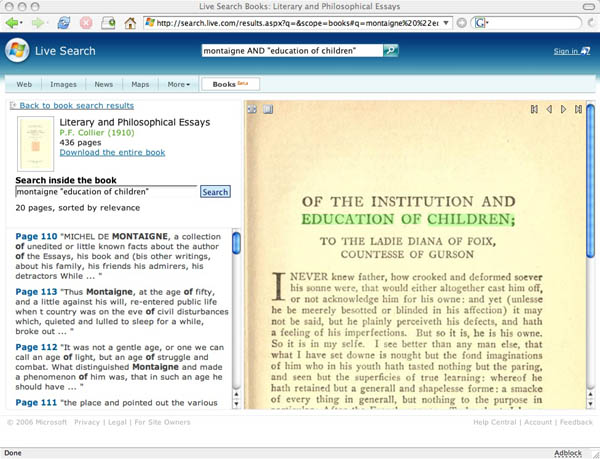
Windows Live Search Books, Microsoft’s answer to Google Book Search, is officially up and running and looks and feels pretty much the same as its nemesis. Being a Microsoft product, the interface is clunkier, and they have a bit of catching up to do in terms of navigation and search options. The one substantive difference is that Live Search is mostly limited to out-of-copyright books — i.e. pre-19231927 editions of public domain works. So the little they do have in there is fully accessible, with PDFs available for download. Like Google’s public domain books, however, the scans are of pretty poor quality, and not searchable. Readers point out that Microsoft, unlike Google, does in fact include a layer of low-quality but entirely searchable OCR text in its public domain downloads.
if:book
A Project of the Institute for the Future of the Book

> the scans are of pretty poor quality,
> and not searchable.
actually, the .pdfs _are_ searchable, as they
contain o.c.r. text. that is the good news…
the o.c.r., however, is embarassingly bad,
almost as bad as the text umichigan puts up,
which is the terrible news…
the scanning projects have to _reverse_course_
on quality, or the whole thing will be shit…
-bowerbird
I’d count needing OCR as _not_ searchable for the general reader.
Couldn’t agree more, though, on the need for quality control. A major part of the rationale for libraries striking these dubious deals with Googlesoft is the enormous cost they save by not having to do the digitization themselves.
But judging by the results, it’s fair to say that they’ve simply shifted the cost to the rest of society.
Or one could say that society doesn’t seem willing to directly fund its libraries to do the kind of job on this that we all agree needs to be done. Is some digital access better than none? Will it get better? Is this what Siva was so irate about when the deal first came down (that libraries should be funded directly to do this themselves, that they simply *should* do it themselves). By the way, public domain works only go up to 1922. Some works from 1923 through 1963 may be public domain if their copyrights were not renewed, but copyright office records that old are, you guessed it, not digitized, so searching them requires hiring someone in DC or a trip to DC yourself.
They don’t need ocr, they are ocred. What are you talking about? In what universe is text that can be searched not “searchable”?
And what do quotations about google’s scanning project (from Michigan) have to do with microsoft’s book search?
Erik,
Naturally, these texts are searchable on the web. What we’re talking about are the downloadable PDFs, which are essentially strings of page images: you can’t search text in a jpeg (or cut-and-paste for that matter). And yes, Google and Microsoft are separate competing enterprises but they represent a single problem: the sectioning off of the public domain (not to mention vast swaths of digital culture) into private commercial enclosures.
Georgia,
1923, duh. Brain slippage. Corrected.
And of course you’re right. Preservation of culture — both analog and digital — ought to be in the charge of a public trust. But here in the States we prefer to let the market take care of such things…
But this is more than a debate about the social contract, or about privatization. I figure the libraries are acting more out of confusion and anxiety than anything else. They simply can’t grasp what it means to build a full-fledged cultural infrastructure for the digital age (to be fair, I think almost no one knows what that would look like). I think the libraries are experiencing as institutions what so many of us are feeling as individuals in the face of massive change — what the hell are we supposed to do with all the old forms and practices in such a radically new environment? What does it mean to be a library today, let alone in the future?
Big tech companies like Google or Microsoft sweep in, seeming to have all the answers. And so we gratefully entrust them with our cultural (not to mention personal) data, figuring they’ll do a far better job with it than we ever could. But we don’t really comprehend the long-term implications of what we’re doing.
Maybe there is a difference between the pdfs, but the ones I have downloaded have an overlay of invisible text which is searchable, which is pretty typical of these sort of pdfs. So you could certainly build a better (or worse) search engine on top of this oca data. If you are unhappy with the quality of the ocr, the image files made available are certainly of high enough quality to do your own ocr on them.
I understand what you are getting at with google & oca but the quality of the scanning is vastly different and to pretend otherwise is nonsense. There is also a vast difference in the aims of the projects & availability of the data.
I stand corrected. I tried one again — a strange old edition of Moby-Dick that seems to start halfway through the text — and you’re right, there is that layer of ocr. On Google PDFs there definitely is not.
I’ll grant that this does underscore the different focus of the Google and Microsoft/OCA digitization projects. But neither is creating the library we need.
Actually, many copyright records (including book renewal records) are digitized, though not officially. See http://onlinebooks.library.upenn.edu/cce/ for details.
Thanks for the correction, and apologies if I was a bit testy.
Instead of complaining, I would like to see some experimentation on how book material should appear online.
The OCA books are available in a variety of formats, and there are lots and lots of them. If you don’t like the OCR, well, do something better.
The libraries are doing their part (though I complain about their accepting restrictions), and we now have mass scanning proceeding. Key now is to make a future for the book form that leverages the new technologies.
let the games begin.
-brewster
Thanks, Brewster, for bringing this up. Experimenting with the book form online is what we’re all about here, though we (mainly me) sometimes get caught up in the politics of digitization and preservation. The issues are of course all interconnected.
What I didn’t get into in this initial posting, and which is usually front and center among my concerns, is the networkiness of text. All of our experiments at the Institute look at what happens when reading and writing take place in a network context — what happens when the book becomes a place on the network rather than a discrete object in your hand. So far, we’ve found that it becomes something between a book and a conversation. Curious to hear your thoughts on this, and how they might be impacting the development of the OCA…
“…between a book and a conversation”
Perhaps another layer here is the interplay of print and screen versions. Is Live Search Books really also a front end for print-on-demand? What if the search term also brings up current POD titles and Microsoft has a bit of sales of those hard copies? What if venders also recapture and supply bound versions of the popular out-of-copy-right screen books? Are the library scans really germinating a new stream of printing? Are production book scanners really printing presses? The hybrid could also be new interplays between print and screen searching, between on-line writing and print.
brewster said:
> Instead of complaining, I would like to see
> some experimentation on how book material
> should appear online.
brewster, i’ve put a number of demo-books online,
even including your own “the open library”…
> http://www.greatamericannovel.com/tolbk/tolbkp023.html
> http://www.greatamericannovel.com/mabie/mabiep123.html
> http://www.greatamericannovel.com/myant/myantp123.html
> http://www.greatamericannovel.com/sgfhb/sgfhbp123.html
> http://www.greatamericannovel.com/ahmmw/ahmmwp023.html
so i’m not just “complaining”…
the essence of my approach is an atomistic one
which enables the end-user to remix most freely,
meaning that each image-scan needs its own url
— one people know is stable and long-lasting —
and that the text needs to be delivered _as_ text,
and in a much smoother form than the raw o.c.r.,
a form that enables print-out as a polished book.
don’t say it’s impossible. i can, and will, show you.
i can also do “networking” around the online copy,
of the kind that ben is talking about, but i wonder
if there is any _need_ for that, at this time anyway.
i have a thick skin, so i don’t take umbrage at things,
but i suggest you take a good hard look at your o.c.r.
you are dropping the hyphens on end-line hyphenates;
you’re losing the paragraph indentations, which means
the text on each page becomes one big long paragraph;
and you’re missing em-dashes. and i discovered all this
in just a few minutes of close examination of a few books.
so i tell you this as friendly advice, not as “complaining”:
you need to reverse course and make quality a priority…
-bowerbird