
Gutenkarte is an effort to map books by MetaCarta. The website takes text from books in Project Gutenberg, searches them for the appearance of place names, and plots them on a map of the world using their own GeoParser API, creating an astonishing visualization of the world described in a text. Here, for example, is a map of Edward Gibbon’s Decline and Fall of the Roman Empire:
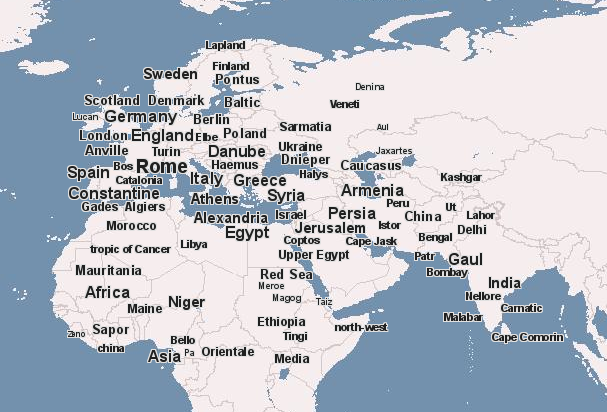
(Click on the picture to view the live map.) It’s not perfect yet: note that “china” is in the Ivory Coast, and “Asia” seems to be located just off the coast of Cameroon. But the map does give an immediate sense of the range of Gibbon’s book: in this case, the extent of the Roman world. The project is still in its infancy: eventually, users will be able to correct mistakes.
Gutenkarte suggests ways of looking at texts not dissimilar from that of Franco Moretti, who in last year’s Graphs, Maps, Trees: Abstract Models for Literary History (discussed by The Valve here) discussed how making maps of places represented in literature could afford a new way of discussing texts. Here, for example, is a map he constructed of Parisian love affairs in the novel, demonstrating that lovers were usually separated by the Seine:
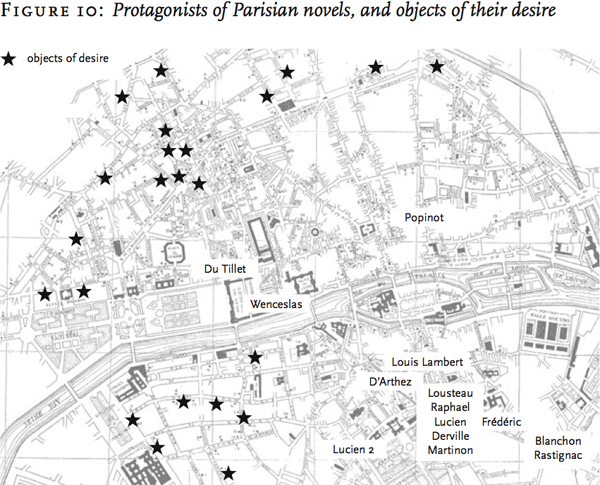
(from the “Maps” chapter, online here if you have university access to the New Left Review.) Moretti constructed his maps by hand, with the help of grad student labor; it will be interesting to see if Gutenkarte will make this sort of visualization accessible to all.
Great post Dan. This type of work is exactly what I am hoping gets made, after we attended the map maker panel at the hyperlinked conference. I hope and expect that this is only the beginning.
it was just two weeks ago, in response to a
“books reading each other” challenge based
on kevin kelly’s article in the new york times,
that i laid out a scenario just like this one
to obtain precisely this result. i used to be
years ahead of my time. now it seems reality
has finally started catching up with me… ;+)
http://onlinebooks.library.upenn.edu/webbin/bparchive?year=2006&post=2006-05-31,2
also of interest here is that the gutenkarte
example is working with plain-ascii content.
i won’t bother to duplicate the comment
in the recent “semantic web” thread, but
it’s just silly — i would say “ridiculous”,
but i’m trying to be more tactful here —
to think that people will mark up our text.
even if we _could_ (and i think that question
is far from having been settled), it’s simply
much too much work for it to be “expected”.
the world is generating text at a rate that
makes it impossible for us to mark it all up.
what this means is that we have to program
routines that analyze that unstructured text
in real-time. like this “gutenkarte” does.
of course, what _that_ means is that we can
tell everyone “not to bother” to do markup
in the first place, since we are going to
have to assume they didn’t do it anyway…
or they did it, but incorrectly… or they
didn’t happen to code the variables we want…
the semantic web is a great idea. but _not_
the way it is currently being conceptualized by
technoids who think “markup is the answer”
to every question. at some time down the line,
when markup is shown to be so unnecessary,
they will have to answer for their attitude that
we should’ve spent valuable time applying it…
-bowerbird
p.s. if you don’t go read that bookpeople post,
at least google for “unstructured data retrieval”
and “jon udell” and “irving wladawsky-berger”.