
Heat and the Heartbeat of the City, a site created by Andrea Polli and commissioned by New Radio and Performing Arts, Inc. for its Turbulence web site. Has created a multimedia narrative that imagines the impact global warming will have on the city. The site presents sonifications (sound compositions created by the translation of data to sound) by Andrea Polli and a series of video interviews with Dr. Cynthia Rosenzwieg regarding the dramatic climate changes that will take place over the next 85 years. The project focuses on Central Park, “one of the country’s first locations for climate monitoring. As you listen, you will travel forward in time at an accelerated pace and experience an intensification of heat in sound.”
Monthly Archives: June 2005
the state of the blog: past, present & future

Since Ben’s on vacation (you may have noticed the crickets chirping in his absence), I’ve been in charge of pruning the comment- and trackback-spam that if:book and the rest of our website generates. Hopefully, you haven’t noticed much of this around here, but it arrives in ever-increasing volume: lately, we’ve been getting upwards of twenty comment-spams per day. They’ve become increasingly less coherent: while once they attempted to cajole our visitors to try out dubious sexual aids or patronize online casinos, the latest batch have been streams of random letters linking to websites that don’t seem to exist.
To combat the problem (which I imagine is much the same at any blog), we’ve installed a Movable Type plugin that filters comments and trackbacks. It does a pretty good job: like a spam filter in a mail program, it can guess what spam is, and it learns quickly. One curious piece of its method, however, might have wider repercussions for how we read & use blogs: it automatically suspects comments made on older posts to be comment spam. This is, by and large, correct: there aren’t a lot of people finding our old posts and leaving comments on them. But this does feel like we’re increasingly killing off old discussions. This ties into my musings from two weeks back, when I wondered how well blogs function as an archive.
A discussion at Slashdot zooms out to look at the ever decreasing signal-to-noise ratio from the soi-disantblogosphere as a whole. Spam blogs – often created to drive up Google rankings, for example – are becoming ever more common; just as it’s simple for you to create a blog, it’s simple for a robot to create a thousand. At what point does the sheer volume of spam start turning users away?
A decent guess, if the history of forms on the web is any indicator, is that something new will arise. Mentioned in the Slashdot discussion is Usenet, the newsgroup-based discussion system. Spam first reared its ugly head on Usenet, and by the late 1990s had almost consumed it. As the level of spam rose, users departed – some, undoubtedly, to the comparatively safer environs of the blogosphere. What comes after blogs?
While on the history of blogs: Matt Sharkey has an interesting history of suck.com (here helpfully archived by its creator, Carl Steadman)
. Suck wasn’t a blog as we know them (readers could email the author, but not directly leave comments for others to see), but it did premiere (in 1995) what would become a key concept of the blog, having fresh concept daily. It also brought snarky semi-anonymous commentators to the Web, and the idea of using hyperlinks for humor. They did get in five solid years, though, and the site is arguably an important milestone in the history of how we read online. Browsing through Steadman’s archive provides food for thought about archives on the web: while it’s still entertaining, you quickly notice that almost every one of the links is broken. Nothing lasts forever.
total recall: managing the memory machine
Bodies in Motion: Memory, Personalization, Mobility and Design, A conference currently taking place at Banff explores the possibility of “total data memory.” The conference gathers together nanotechnology researchers, medical researchers, and historians to examine the vast realm of memory materials gathered from increasingly ubiquitous devices such as: sensors, personal recording devices, and surveillance technologies. The conference imagines a world where information will be gathered by everything around us. Our clothes, the walls, we may even find sensors embedded in our bodies. This plethora of information could be used to construct an exhaustive virtual history. But is that something we want?
What drives the contemporary desire in the technology world for total data memory? How does data memory sit beside new kinds of memory capacities in other materials? Memory is closely linked to histories and the interpretations of history. Some of the best mobile experiences combine local memory, histories and place. What models of memory and mind are used in designing technologies that remember? What are the ethical implications of memory machines? What does this mean in time of war, increased security? How do we include the need, capacity, and desire to forget? How do we include trauma?
Marvelous summary of the questions facing us in the coming age of total recall.
get on your digital soapbox

“What would you say, given one free minute of anonymous, uncensored speech?” the people at One Free Minute want to know. Their project gives you a chance to speak your mind loudly and anonymously in “America’s demographically average city: Columbus, Ohio.”
According to the site: One Free Minute began as a simple concept: what would happen if the remote speech were connected to public space? Since then it has branched out to be an examination of public speech, an exploration of how cellular technology affects human communication in both negative and positive ways, a hand-made fibreglass sculpture, a web site, a bunch of phone lines, a whole lot of server bandwidth… you get the idea.
The One Free Minute mobile sculpture has a cell phone inside connected to a 200 watt amplifier and speaker. Callers remain connected for exactly one minute and their calls are broadcast through the sculpture’s red, Victrola-like speaker. These micro-speeches are either performed live, or broadcast from taped messages. Visit the site to hear examples and to find out how to participate.
who owns ideas?
There’s an interesting intellectual property debate going on over at Technology Review. Lawrence Lessig hones in on the basic problem:
It is the nature of digital technologies that every use produces a copy. Thus, it is the nature of a copyright regime like the United States’, designed to regulate copies, that every use in the digital world produces a copyright question: Has this use been licensed? Is it permitted? And if not permitted, is it “fair”? Thus, reading a book in analog space may be an unregulated act. But reading an e-book is a licensed act, because reading an e-book produces a copy. Lending a book in analog space is an unregulated act. But lending an e-book is presumptively regulated. Selling a book in analog space is an unregulated act. Selling an e-book is not. In all these cases, and many more, ordinary uses that were once beyond the reach of the law now plainly fall within the scope of copyright regulation. The default in the analog world was freedom; the default in the digital world is regulation.
I’m going on a brief hiatus, so that’ll be my last link for a little while. But keep checking back – Bob, Kim and Dan will be keeping the home fires burning.
how the web changes your reading habits
An article in yesterday’s Christian Science Monitor looks at two research projects currently underway in Palo Alto, California – one at Xerox PARC, the other at Stanford. Both are building tools and devising methods to improve online reading, albeit by different approaches. The PARC project is developing ScentHighlights, an “enhanced skimming” function based on keywords and the associative processes of the human brain. On paper, we highlight important passages, or attach sticky notes, to make them more readily retrievable later on when we’re re-reading, studying, or compiling notes. The PARC researchers are taking this a few steps further, exploiting the unique properties (and addressing the unique challenges) of the online reading environment. With ScentHighlights, the computer observes what the reader is highlighting and selects other passages that it thinks might be relevant or useful:
We perform the conceptual highlighting by computing what conceptual keywords are related to each other via word co-occurrence and spreading activation. Spreading activation is a cognitive model developed in psychology to simulate how memory chunks and conceptual items are retrieved in our brain.
While the PARC team is focused on deepening the often fractured experience of reading online, where the amount of text is overwhelming, the Stanford project is experimenting with a method for sustained reading in an environment that can barely handle text at all: the tiny screens of cell phones and mobile devices. Using a technique called RSVP (Rapid Serial Visual Presentation), BuddyBuzz flashes words on the screen one at a time. It takes some getting used to, but apparently, readers can absorb up to 1,000 words per minute. Speed is adjustable, and the program is already set to make the tiny, natural pauses that come at commas and periods. The initial release of BuddyBuzz will syndicate stories from Reuters, CNET and a handful of popular blogs.
american libraries are wired, with doors wide open
From today’s NY Times: “Almost All Libraries Offer Free Web Access”:
The study, which was conducted by researchers at Florida State University, found that 98.9 percent of libraries offer free public Internet access, up from 21 percent in 1994 and 95 percent in 2002. It also found that 18 percent of libraries have wireless Internet access and 21 percent plan to get it within the next year.
Even in an age of online reading, the library still has tremendous significance as a physical commons. When wi-fi coverage in cities becomes comprehensive, we should still be able to get free access at our local library. Another way that public libraries can stay relevant is to offer free on-site access to pay services: things like Lexis-Nexis, subscription-only web periodicals, and even web-delivered movies and television.
GooglePorn.com?
They say that porn drives technology, but could it possibly figure into Google’s expansion into online payment systems? Would that be the end of the cute, cuddly Google we’ve all come to know and love – our most constant companion on the web? Sam Sugar, author of the adult industry-watching blog SugarBank, says Google would be foolish not to capitalize on this massive underground market, routinely shunned by “respectable” services like PayPal. In an open letter to Google’s CEOs, Sugar lays out his arguments and explains how porn could catapult Google to the cutting edge of ecommerce, in much the same way that it helped VHS outmaneuver Betamax.
Banking is a perennial thorn in the side of even the largest and most successful adult websites. All adult companies are overcharged by merchant banks poorly equipped to deal with transactions they consider to be ‘high-risk’.
Before PayPal withdrew from offering billing services to adult companies (around the time they were acquired by eBay), they were the preferred customer choice for the websites that offered them as a payment option.
It’s hard to justify PayPal’s withdrawl on ‘moral’ grounds given the volume of pornography sold via eBay. The logical assumption is that PayPal’s decision to ban adult transactions is due to an inability to handle them well. What is beyond question is that their decision loses them billions a year.
Consumers don’t find adult websites easy to trust, and would welcome the ability to buy adult material without sharing their financial information with companies they’re unsure of. Google is universally trusted and so, when you launch the Google billing system, the adult industry will rush to use it.
(via Searchblog, who reports that Google already owns GooglePorn.com and similar domains.. intrigue!)
google maps with u.s. census data
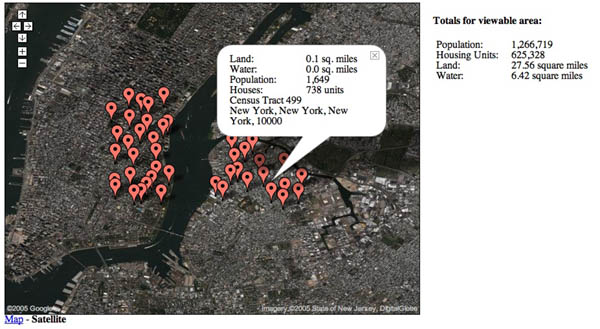
Another great hack: gCensus.com. The thing I like about this is the fluidity of the data changing across scale and location. As you zoom in and out, or drag across the map, the statistical markers re-cluster, while to the right, “totals for viewable area” (population, housing units, land/water area) shift smoothly. You feel as though you are using a highly sensitive instrument.
Hack I’d like to see: real-time birth/death map (using hospital data).
weaving libraries into the web
A great feature of the Firefox web browser is the little search window built right into the toolbar next to the address field. It’s set to Google as a default, but you can add other common search engines or knowledge bases like Yahoo, IMDB, Amazon, eBay, Wikipedia, dictionaries and others – a customized reference suite right in your browser. What if you could put a card catalogue in there too? John Wohlers, of the Todd Library at Waubonsee Community College in Sugar Grove, Illinois has built a searchlet that effectively does this. It’s not like Google Print, where you can actually browse scanned copies of the book, but it takes a step toward integrating libraries with the web – an important move if they are to remain relevant in a world where browsers and search engines are the primary research tools.
Wohlers is also working on building library search into desktop tools. Windows users can find instructions here for putting the Todd Library catalogue into your Microsoft Office 2003 Research Pane.
(via The Shifted Librarian)