
Interesting bit of media industry theater here. I’m here in the New York Public Library, one of the city’s great temples to the book, where Google has assembled representatives of the book business to undergo a kind of group massage. A pep talk for a timorous publishing industry that has only barely dipped its toes in the digital marketplace and can’t decide whether to regard Google as savior or executioner. The speaker roster is a mix of leading academic and trade publishers and diplomatic envoys from the techno-elite. Chris Anderson, Cory Doctorow, Seth Godin, Tim O’Reilly have all spoken. The 800lb. elephant in the room is of course the lawsuits brought against Google (still in the discovery phase) by the Association of American Publishers and the Authors’ Guild for their library digitization program. Doctorow and O’Reilly broached it briefly and you could feel the pulse in the room quicken. Doctorow: “We’re a cabal come over from the west coast to tell you you’re all wrong!” A ripple of laughter, acid-laced. A little while ago Michael Holdsworth of Cambridge University Press pointed to statistics that suggest that Book Search is driving up their sales… Some grumble that the publishers’ panel was a little too hand-picked.
Google’s tactic here seems simultaneously to be to reassure the publishers while instilling an undercurrent of fear. Reassure them that releasing more of their books in a greater variety of forms will lead to more sales (true) — and frightening them that the technological train is speeding off without them (also true, though I say that without the ecstatic determinism of the Google folks. Jim Gerber, Google’s main liason to the publishing world, opened the conference with a love song to Moore’s Law and the gigapixel camera, explaining that we’re within a couple decades’ reach of having a handheld device that can store all the content ever produced in human history — as if this fact alone should drive the future of publishing). The event feels more like a workshop in web marketing than a serious discussion about the future of publishing. It’s hard to swallow all the marketing speak: “maximizing digital content capabilities,” “consolidation by market niche”; a lot of talk of “users” and “consumers,” but not a whole lot about readers. Publishers certainly have a lot of catching up to do in the area of online commerce, but barely anyone here is engaging with the bigger questions of what it means to be a publisher in the network era. O’Reilly sums up the publisher’s role as “spreading the knowledge of innovators.” This is more interesting and O’Reilly is undoubtedly doing more than almost any commercial publisher to rethink the reading experience. But most of the discussion here is about a culture industry that seems more concerned with salvaging the industry part of itself than with honestly rethinking the cultural part. The last speaker just wrapped up and it’s cocktail time. More thoughts tomorrow.
Category Archives: search
has google already won?
Rich Skrenta, an influential computer industry insider, currently co-founder and CEO of Topix.net and formerly a big player at Netscape, thinks it has, crowning Google king of the “third age of computing” (IBM and Microsoft being the first and second). Just the other day, there was a bit of discussion here about whether Google is becoming a bona fide monopoly — not only by dint of its unrivaled search and advertising network, but through the expanding cloud of services that manage our various personal communication and information needs. Skrenta backs up my concern (though he mainly seems awed and impressed) that with time, reliance on these services (not just by individuals but by businesses and oranizations of all sizes) could become so total that there will effectively be no other choice:
Just as Microsoft used their platform monopoly to push into vertical apps, expect Google to continue to push into lucrative destination verticals — shopping searches, finance, photos, mail, social media, etc. They are being haphazard about this now but will likely refine their thinking and execution over time. It’s actually not inconceivable that they could eventually own all of the destination page views too. Crazy as it sounds, it’s conceivable that they could actually end up owning the entire net, or most of what counts.
The meteoric ascendance of the Google brand — synonymous in the public mind with best, quickest, smartest — and the huge advantage the company has gained by becoming “the start page for the Internet,” means that its continued dominance is all but assured. “Google is the environment.” Others here think these predictions are overblown. To me they sound frighteningly plausible.
people-powered search (part 1)
Last week, the London Times reported that the Wikipedia founder, Jimbo Wales, was announcing a new search engine called “Wikiasari.” This search engine would incorporate a new type of social ranking system and would rival Google and Yahoo in potential ad revenue. When the news first got out, the blogosphere went into a frenzy; many echoing inaccurate information – mostly in excitement – causing lots confusion. Some sites even printed dubious screenshots of what they thought was the search engine.
Alas, there were no real screenshots and there was no search engine… yet. Yesterday, unable to make any sense what was going on by reading the blogs, I looked through the developer mailing list and found this post by Jimmy Wales:
The press coverage this weekend has been a comedy of errors. Wikiasari was not and is not the intended name of this project… the London Times picked that off an old wiki page from back in the day when I was working on the old code base and we had a naming contest for it. […] And then TechCrunch ran a screenshot of something completely unrelated, thus unfortunately perhaps leading people to believe that something is already built about about to be unveiled. No, the point of the project is to build something, not to unveil something which has already been built.
And in the Wikia search webpage he explains why:
Search is part of the fundamental infrastructure of the Internet. And, it is currently broken. Why is it broken? It is broken for the same reason that proprietary software is always broken: lack of freedom, lack of community, lack of accountability, lack of transparency. Here, we will change all that.
So there is no Google-killer just yet, but something is brewing.
From the details that we have so far, we know that this new search engine will be funded by Wikia Inc, Wales’ for-profit and ad-driven MediaWiki hosting company. We also know that the search technology will be based on Nutch and Lucene – the same technology that powers Wikipedia’s search. And we also know that the search engine will allow users to directly influence search results.
I found interesting that in the Wikia “about page”, Wales suggests that he has yet to make up his mind on how things are going to work, so suggestions appear to be welcome.
Also, during the frenzy, I managed to find many interesting technologies that I think might be useful in making a new kind of search engine. Now that a dialog appears to be open and there is good reason to believe a potentially competitive search engine could be built, current experimental technologies might play an important role in the development of Wikia’s search. Some questions that I think might be useful to ponder are:
Can current social bookmarking tools, like del.icio.us, provide a basis for determining “high quality” sites? Will using Wikipedia and it’s external site citing engine make sense for determining “high quality” links? Will using a Digg-like, rating system result spamless or simply just low brow results? Will a search engine dependant on tagging, but no spider be useful? But the question I am most interested in is whether a large scale manual indexing lay the foundation for what could turn into the Semantic Web (Web 3.0)? Or maybe just Web 2.5?
The most obvious and most difficult challenge for Wikia, besides coming up with a good name and solid technology, will be with dealing with sheer size of the internet.
I’ve found that open-source communities are never as large or as strong as they appear. Wikipedia is one of the largest and one of the most successful online collaborative projects, yet just over 500 people make over 50% of all edits and about 1400 make about 75% of all edits. If Wikia’s new search engine does not generate a large group of users to help index the web early on, this project will not survive; A strong online community, possibly in a magnitude we’ve never seen before, might be necessary to ensure that people-powered search is of any use.
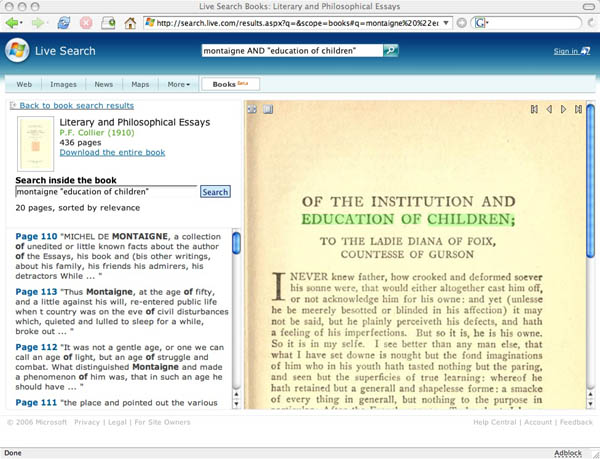
microsoft launches live search books
Windows Live Search Books, Microsoft’s answer to Google Book Search, is officially up and running and looks and feels pretty much the same as its nemesis. Being a Microsoft product, the interface is clunkier, and they have a bit of catching up to do in terms of navigation and search options. The one substantive difference is that Live Search is mostly limited to out-of-copyright books — i.e. pre-19231927 editions of public domain works. So the little they do have in there is fully accessible, with PDFs available for download. Like Google’s public domain books, however, the scans are of pretty poor quality, and not searchable. Readers point out that Microsoft, unlike Google, does in fact include a layer of low-quality but entirely searchable OCR text in its public domain downloads.
how would you design the iraq study group report for the web?
The “Iraq Study Group Report” paperback could have been wrapped in a brown paper bag, its title scrawled in Magic Marker. It would still sell. This is a book, unlike trillions of others on the market, whose substance and national import sell it, not its cover…Disproving the adage, this genre of book can indeed be judged by its cover. From the reports on the Warren Commission to Watergate, Iran-contra and now the Iraq war, such books are anomalies for a publishing industry that churns out covers intended to seduce readers, to reach out and grab them, and propel them to the cash register.




How would you design an unauthorized web edition of the ISG Report? Would you keep to the sober, no-nonsense aesthetic of the iconic print editions of past government documents like the 9/11 Commission Report or the Warren Commission Report? Or would you shake things up? A far more interesting question: what functionality would you add? What kind of discussion capabilities would you build into it? Who would you most like to see annotate or publicly comment on the document?
The electronic edition that has been making the rounds is an austere PDF made available by the United States Institute of Peace. A far more useful resource for close reading of the text was put out by Vivismo as a demonstration of its new Velocity Search Engine. They crawled the PDF and broke it into individual paragraphs, adding powerful clustered search tools.
The US Government Printing Office has a slew of public documents available on its website, mostly as PDFs or bare-bones HTML pages. How should texts of “national import” be reconceived for the network?
no, dammit that’s not what i meant . . . .
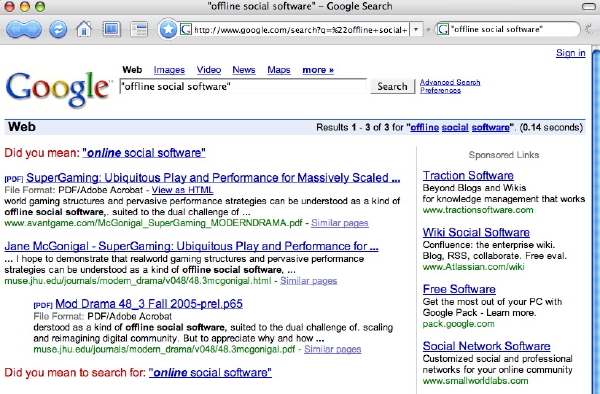
I had a very interesting discussion in London the other day with Seb Mary, a brilliant young woman who is exploring ways of using the online world to encourage new forms of community in the offline world. Mary’s most exciting initiatives, which are quite relevant to our interests here at the institute, are still under wraps and i promised not to write about them yet, but she did mention having coined the phrase “offline social software.” Amazingly when i typed the phrase into Google i got back “Did you mean “online social software.” Is Google trying to tell us something? Is the very concept of an offline existence unthinkable in the Googlesphere?
microsoft steps up book digitization
Back in June, Microsoft struck deals with the University of California and the University of Toronto to scan titles from their nearly 50 million (combined) books into its Windows Live Book Search service. Today, the Guardian reports that they’ve forged a new alliance with Cornell and are going to step up their scanning efforts toward a launch of the search portal sometime toward the beginning of next year. Microsoft will focus on public domain works, but is also courting publishers to submit in-copyright books.
Making these books searchable online is a great thing, but I’m worried by the implications of big coprorations building proprietary databases of public domain works. At the very least, we’ll need some sort of federated book search engine that can leap the walls of these competing services, matching text queries to texts in Google, Microsoft and the Open Content Alliance (which to my understanding is mostly Microsoft anyway).
But more important, we should get to work with OCR scanners and start extracting the texts to build our own databases. Even when they make the files available, as Google is starting to do, they’re giving them to us not as fully functioning digital texts (searchable, remixable), but as strings of snapshots of the scanned pages. That’s because they’re trying to keep control of the cultural DNA scanned from these books — that’s the value added to their search service.
But the public domain ought to be a public trust, a cultural infrastructure that is free to all. In the absence of some competing not-for-profit effort, we should at least start thinking about how we as stakeholders can demand better access to these public domain works. Microsoft and Google are free to scan them, and it’s good that someone has finally kickstarted a serious digitization campaign. It’s our job to hold them accountable, and to make sure that the public domain doesn’t get redefined as the semi-public domain.
phony bookstore
Since it’s trash the ebooks week here at if:book, I thought I’d point out one more little item to round out our negative report card on the new Sony Reader. ![]() In a Business Week piece, amusingly titled “Gutenberg 1, Sony 0,” Stephen Wildstrom delivers another less than favorable review of Sony’s device and then really turns up the heat in his critique of their content portal, the Connect ebook store:
In a Business Week piece, amusingly titled “Gutenberg 1, Sony 0,” Stephen Wildstrom delivers another less than favorable review of Sony’s device and then really turns up the heat in his critique of their content portal, the Connect ebook store:
These deficits, however, pale compared to Sony’s Connect bookstore, which seems to be the work of someone who has never visited Amazon.com. Sony offers 10,000 titles, but that doesn’t mean you will find what you want. For example, only four of the top 10 titles on the Oct. 1 New York Times paperback best-seller list showed up. On the other hand, many books are priced below their print equivalents–most $7.99 paperbacks go for $6.39–and can be shared among any combination of three Readers or pcs, much as Apple iTunes allows multiple devices to share songs.
The worst problem is that search, the essence of an online bookstore, is broken. An author search for Dan Brown turned up 84 books, three of them by Dan Brown, the rest by people named Dan or Brown, or sometimes neither. Putting a search term in quotes should limit the results to those where the exact phrase occurs, but at the Sony store, it produced chaos. “Dan Brown” yielded 500 titles, mostly by people named neither Dan nor Brown. And the store doesn’t provide suggestions for related titles, reviews, previews–all those little extras that make Amazon great.
Remember that you can’t search texts at all on the actual Reader, though Sony does let you search books that you’ve purchased within your personal library in the Connect Store. But it’s a simple find function, bumping you from instance to instance, with nothing even approaching the sophisticated concordances and textual statistics that Amazon offers in Search Inside. You feel the whole time that you’re looking through the wrong end of the telescope. Such a total contraction of the possibilities of books. So little consideration of the complex ways readers interact with texts, or of the new directions that digital and networked interaction might open up.
literary zeitgest, google-style
At the Frankfurt Book Fair this week, Google revealed a small batch of data concerning use patterns on Google Book Search: a list of the ten most searched titles from September 17 to 23. Google already does this sort of snapshotting for general web search with its “zeigeist” feature, a weekly, monthly or annual list of the most popular, or gaining, search queries for a given period — presented as a screengrab of the collective consciousness, or a slice of what John Battelle calls “the database of intentions.” The top ten book list is a very odd assortment, a mix of long tail eclecticism and current events:
Diversity and Evolutionary Biology of Tropical Flowers By Peter K. Endress
Merriam Webster’s Dictionary of Synonyms
Measuring and Controlling Interest Rate and Credit Risk By Frank J. Fabozzi, Steven V. Mann, Moorad Choudhry
Ultimate Healing: The Power of Compassion By Lama Zopa Rinpoche; Edited by Ailsa Cameron
The Holy Qur’an Translated by Abdullah Yusuf Ali
Peterson’s Study Abroad 2006
Hegemony Or Survival: America’s Quest for Global Dominance By Noam Chomsky
Merriam-Webster’s Dictionary of English Usage
Perrine ‘s Literature: Structure, Sound, and Sense By Thomas R Arp, Greg Johnson
Build Your Own All-Terrain Robot By Brad Graham, Kathy McGowan
(reported in Reuters and InfoWorld)
google and the future of print
Veteran editor and publisher Jason Epstein, the man who first introduced paperbacks to American readers, discusses recent Google-related books (John Battelle, Jean-Noël Jeanneney, David Vise etc.) in the New York Review, and takes the opportunity to promote his own vision for the future of publishing. As if to reassure the Updikes of the world, Epstein insists that the “sparkling cloud of snippets” unleashed by Google’s mass digitization of libraries will, in combination with a radically decentralized print-on-demand infrastructure, guarantee a bright future for paper books:
[Google cofounder Larry] Page’s original conception for Google Book Search seems to have been that books, like the manuals he needed in high school, are data mines which users can search as they search the Web. But most books, unlike manuals, dictionaries, almanacs, cookbooks, scholarly journals, student trots, and so on, cannot be adequately represented by Googling such subjects as Achilles/wrath or Othello/jealousy or Ahab/whales. The Iliad, the plays of Shakespeare, Moby-Dick are themselves information to be read and pondered in their entirety. As digitization and its long tail adjust to the norms of human nature this misconception will cure itself as will the related error that books transmitted electronically will necessarily be read on electronic devices.
Epstein predicts that in the near future nearly all books will be located and accessed through a universal digital library (such as Google and its competitors are building), and, when desired, delivered directly to readers around the world — made to order, one at a time — through printing machines no bigger than a Xerox copier or ATM, which you’ll find at your local library or Kinkos, or maybe eventually in your home.
 Predicated on the “long tail” paradigm of sustained low-amplitude sales over time (known in book publishing as the backlist), these machines would, according to Epstein, replace the publishing system that has been in place since Gutenberg, eliminating the intermediate steps of bulk printing, warehousing, retail distribution, and reversing the recent trend of consolidation that has depleted print culture and turned book business into a blockbuster market.
Predicated on the “long tail” paradigm of sustained low-amplitude sales over time (known in book publishing as the backlist), these machines would, according to Epstein, replace the publishing system that has been in place since Gutenberg, eliminating the intermediate steps of bulk printing, warehousing, retail distribution, and reversing the recent trend of consolidation that has depleted print culture and turned book business into a blockbuster market.
Epstein has founded a new company, OnDemand Books, to realize this vision, and earlier this year, they installed test versions of the new “Espresso Book Machine” (pictured) — capable of producing a trade paperback in ten minutes — at the World Bank in Washington and (with no small measure of symbolism) at the Library of Alexandria in Egypt.
Epstein is confident that, with a print publishing system as distributed and (nearly) instantaneous as the internet, the codex book will persist as the dominant reading mode far into the digital age.